Bạn đang xem: Web scraping là gì
Web Scraping là gì?
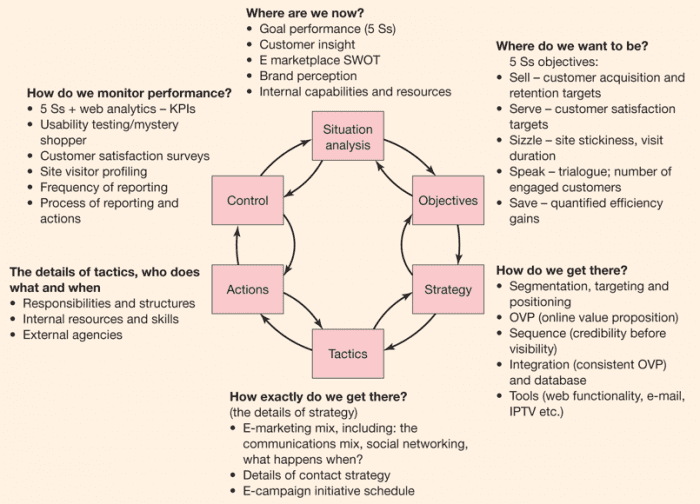
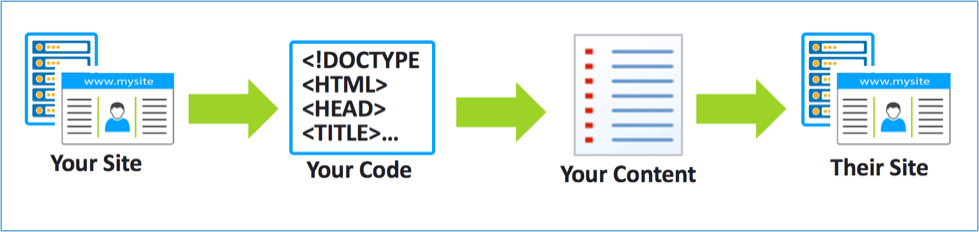
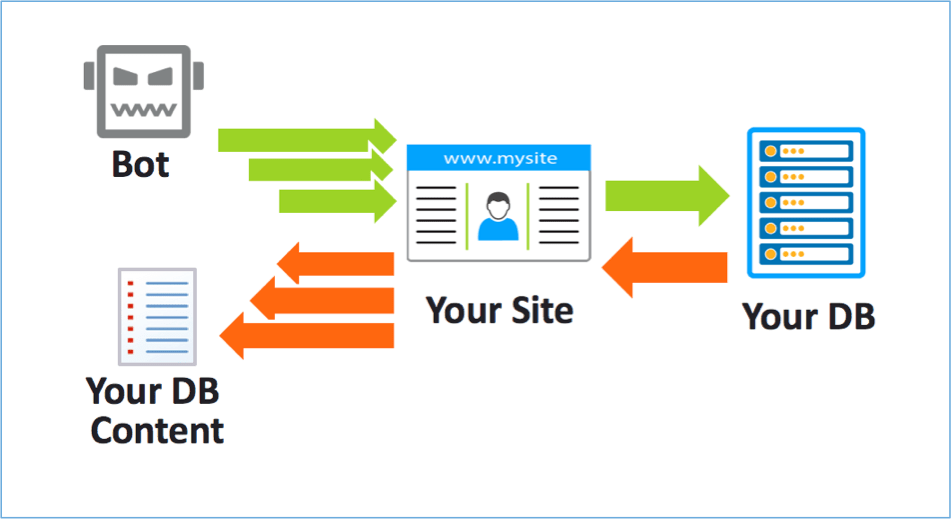
Web scraping là một quá trình tự động thu thập thông tin từ website. Kiểu scraping phổ biến nhất là site scraping, tập trung vào sao chép và đánh cắp nội dung web. Hành vi tái sử dụng nội dung có thể có hoặc không nhận được sự chấp nhận từ chủ sở hữu website.Thông thường, các con bot sao chép dữ liệu bằng cách crawling. Crawl là một thuật ngữ mô tả quá trình thu thập dữ liệu trên website của các con bot. Các con bot truy cập vào mã nguồn website, phân tích cấu trúc, lấy nội dung và đăng tải lên trang khác.
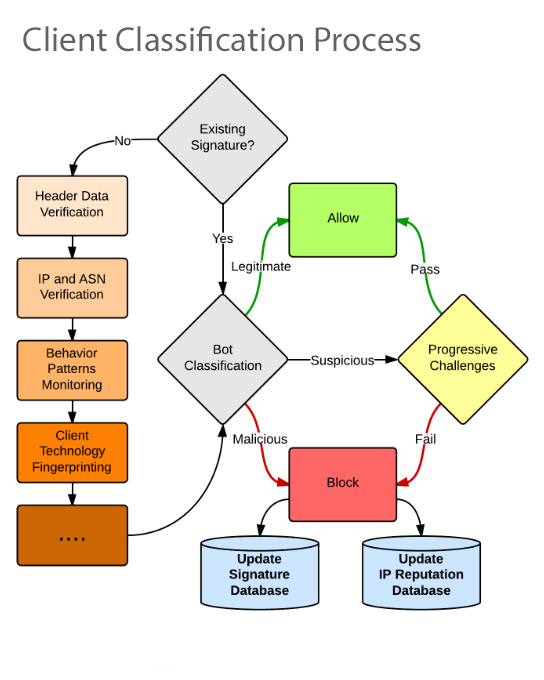
Quy trình phân loại client
Chủ website có thể thực hiện các phương pháp sau để phân loại và giảm thiểu các con bot, bao gồm cả việc phát hiện Scraping Bot: Sử dụng công cụ phân tích – Các công cụ phân tích kiểm tra cấu trúc web request và thông tin header. Kết hợp các thông tin này với thông tin của các con bot trả về, chủ website có thể xác định đâu là con bot hợp pháp, đâu là con bot cần ngăn chặn.
Xem thêm: #1 Quy định Của Pháp Luật Về Hợp đồng Dịch Vụ Là Gì
Xem thêm: đi Tiểu Buốt ở Phụ Nữ Là Bệnh Gì, đái Buốt ở Phụ Nữ
Triển khai cách tiếp cận “thách thức” (challenge-based) – Sử dụng các công nghệ web để đánh giá hành vi của client như nó có hỗ trợ cookie và JavaScript hay không? Chủ website cũng có thể sử dụng CAPTCHA để chặn các một vài cuộc tấn công. Lựa chọn cách tiếp cận hành vi – Hầu hết các con bot đều tự liên kết với các chương trình client gốc như JavaScript, InteExplorer hay Chrome. Nếu đặc điểm của các con bot này khác biệt với client gốc, chủ website có thể sử dụng các điểm bất thường để phát hiện, ngăn chặn và giảm thiểu chúng. Sử dụng robots.txt – Chủ website có thể sử dụng robots.txt để bảo vệ website trước scraping bot, nhưng cách này không có hiệu quả lâu dài. Đây là tệp tin hướng dẫn các con bot thực hiện theo luật định sẵn. Trong một vài trường hợp, một vài con bot độc hại sẽ tìm kiếm thông tin trong robots.txt (thư mục riêng, trang quản trị) mà chủ website không muốn Google đánh chỉ mục và khai thác chúng.
Incapsula
Chuyên mục: Hỏi Đáp