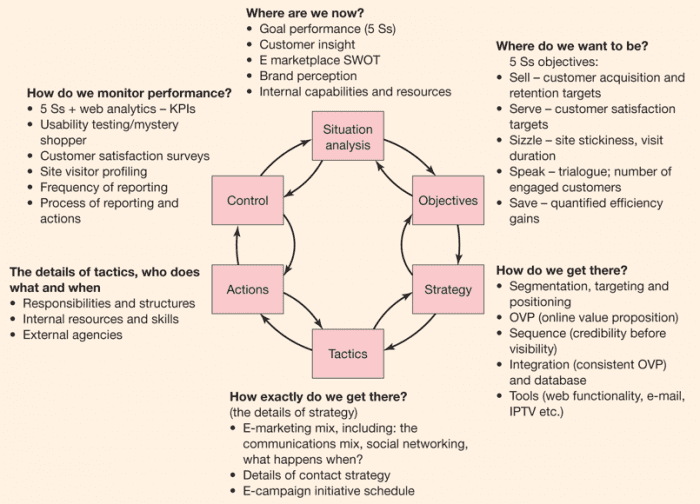
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Bạn đang xem: Reinforcement learning là gì
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Sự khác biệt giữa học tập củng cố dựa trên mô hình và mô hình là gì? Dường như với tôi, bất kỳ người học không có mô hình nào, học qua thử và sai, đều có thể được quy định là dựa trên mô hình. Trong trường hợp đó, …
28 reinforcement-learning comparison model-based model-free
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Mối quan hệ giữa phương pháp học tập chính sách và độ dốc chính sách là gì?
Theo tôi hiểu, Q-learning và độ dốc chính sách (PG) là hai phương pháp chính được sử dụng để giải quyết các vấn đề RL. Trong khi Q-learning nhằm mục đích dự đoán phần thưởng của một hành động nhất định được thực hiện ở một trạng thái nhất định, …
20 reinforcement-learning q-learning policy-gradients comparison
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Tôi muốn tạo ra một AI có thể chơi năm liên tiếp / gomoku. Như tôi đã đề cập trong tiêu đề, tôi muốn sử dụng học tăng cường cho việc này. Tôi sử dụng phương pháp gradient chính sách , cụ thể là REINFORCE, với đường cơ sở. Đối …
20 machine-learning reinforcement-learning game-ai combinatorial-games
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Tôi đang nghiên cứu học tập củng cố và các biến thể của nó. Tôi bắt đầu hiểu được cách các thuật toán hoạt động và cách chúng áp dụng cho MDP. Điều tôi không hiểu là quá trình xác định các trạng thái của MDP. Trong hầu hết các …
14 reinforcement-learning
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Hiệu quả mẫu là gì và làm thế nào để lấy mẫu quan trọng để đạt được nó?
Chẳng hạn, tiêu đề của bài viết này có nội dung: “Diễn viên hiệu quả – Phê bình với phát lại kinh nghiệm”. Hiệu quả mẫu là gì và làm thế nào để lấy mẫu quan trọng để đạt được nó?
14 reinforcement-learning statistical-ai importance-sampling
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Tôi đã xem xét việc học tăng cường, và đặc biệt là chơi xung quanh với việc tạo môi trường của riêng tôi để sử dụng với OpenAI Gym AI. Tôi đang sử dụng các tác nhân từ dự án ổn định_baselines để thử nghiệm với nó. Một điều tôi …
13 machine-learning reinforcement-learning overfitting dropout
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Câu hỏi này liên quan đến Học tập Củng cố và không gian hành động khác nhau / không nhất quán cho mỗi / một số tiểu bang . Ý tôi là gì bởi không gian hành động không nhất quán ? Giả sử bạn có MDP trong đó số …
13 reinforcement-learning
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Xem thêm: Cư Trú Là Gì – Xác định Nơi Cư Trú ổn định
Khi thiết kế các giải pháp cho các vấn đề như Lunar Lander trên OpenAIGym , Học tăng cường là một phương tiện hấp dẫn để cung cấp cho tác nhân quyền kiểm soát hành động đầy đủ để hạ cánh thành công. Nhưng các trường hợp trong đó các …
12 reinforcement-learning ai-design control-theory
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Có cách nào để dạy học tăng cường trong các ứng dụng khác ngoài game không? Các ví dụ duy nhất tôi có thể tìm thấy trên Internet là của các đại lý trò chơi. Tôi hiểu rằng VNC sẽ kiểm soát đầu vào cho các trò chơi thông qua …
12 reinforcement-learning applications
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Làm thế nào để thực hiện một không gian hành động bị hạn chế trong học tập củng cố?
Tôi đang mã hóa một mô hình học tập củng cố với một tác nhân PPO nhờ vào thư viện Tensorforce rất tốt , được xây dựng trên đỉnh của Tensorflow. Phiên bản đầu tiên rất đơn giản và giờ tôi đang lặn vào một môi trường phức tạp hơn, …
12 deep-learning reinforcement-learning
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Tôi đã trải qua quá trình triển khai DQN này và tôi thấy rằng trên dòng 124 và 125 hai mạng Q khác nhau đã được khởi tạo. Từ hiểu biết của tôi, tôi nghĩ rằng một mạng dự đoán hành động phù hợp và mạng thứ hai dự đoán …
12 reinforcement-learning q-learning dqn
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Tôi đang đọc cuốn sách Củng cố học tập: Giới thiệu của Richard S. Sutton và Andrew G. Barto (bản thảo hoàn chỉnh, ngày 5 tháng 11 năm 2017). Trên trang 271, mã giả cho Phương pháp Gradient chính sách Monte-Carlo được trình bày. Nhìn vào mã giả này tôi …
11 reinforcement-learning algorithm rl-an-introduction reinforce
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Là một sinh viên muốn làm việc trên máy học, tôi muốn biết làm thế nào có thể bắt đầu việc học của mình và làm thế nào để theo dõi nó để luôn cập nhật. Ví dụ, tôi sẵn sàng làm việc về các vấn đề RL và MAB, …
11 machine-learning reinforcement-learning research markov-decision-process
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Thuật toán Q-learning dạng bảng được đảm bảo để tìm hàm tối ưu , , với các điều kiện sau (điều kiện Robbins-Monro ) về tốc độ học tập được thỏa mãnQQQQ*Q*Q^* Σtαt( S , một ) = ∞Σtαt(S,một)= =∞sum_ alpha_t(s, a) = infty Σtα2t( s , a ) < …
11 reinforcement-learning q-learning deep-rl proofs function-approximation
Đối với các câu hỏi liên quan đến việc học được kiểm soát bởi sự củng cố tích cực bên ngoài hoặc tín hiệu phản hồi tiêu cực hoặc cả hai, trong đó việc học và sử dụng những gì đã được học cho đến nay xảy ra đồng thời.
Làm thế nào độ dốc chính sách có thể được áp dụng trong trường hợp có nhiều hành động liên tục?
Tối ưu hóa chính sách khu vực đáng tin cậy (TRPO) và tối ưu hóa chính sách gần (PPO) là hai thuật toán độ dốc chính sách tiên tiến. Thông thường, khi sử dụng một hành động liên tục duy nhất, bạn sẽ sử dụng một số phân phối xác …
11 deep-learning reinforcement-learning trpo
Xem thêm: Chuyển Nhượng Là Gì, Nghĩa Của Từ Chuyển Nhượng
Khi sử dụng trang web của chúng tôi, bạn xác nhận rằng bạn đã đọc và hiểu Chính sách cookie và Chính sách bảo mật của chúng tôi.
Chuyên mục: Hỏi Đáp