Giới thiệu về LSTM
Bài trước mình đã giới thiệu về recurrent neural network (RNN). RNN có thể xử lý thông tin dạng chuỗi (sequence/ time-series). Như ở bài dự đoán hành động trong video ở bài trước, RNN có thể mang thông tin của frame (ảnh) từ state trước tới các state sau, rồi ở state cuối là sự kết hợp của tất cả các ảnh để dự đoán hành động trong video.
Bạn đang xem: Lstm là gì
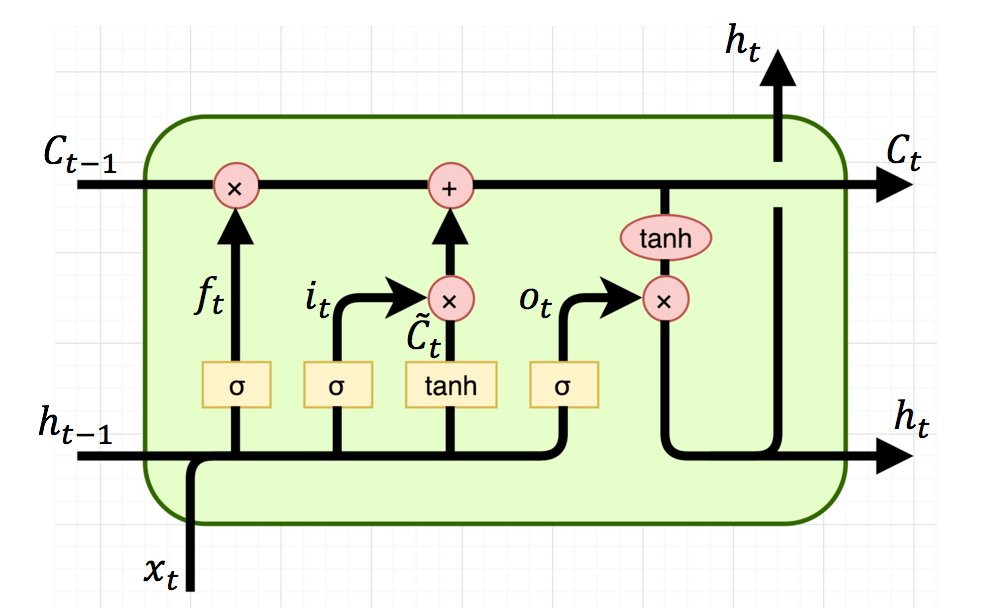
Các đọc biểu đồ trên: bạn nhìn thấy kí hiệu sigma, tanh ý là bước đấy dùng sigma, tanh activation function. Phép nhân ở đây là element-wise multiplication, phép cộng là cộng ma trận.
f_t, i_t, o_t tương ứng với forget gate, input gate và output gate.
Forget gate: displaystyle f_t = sigma(U_f*x_t + W_f*h_{t-1} + b_f)Input gate: displaystyle i_t = sigma(U_i*x_t + W_i*h_{t-1} + b_i) Output gate: displaystyle o_t = sigma(U_o*x_t + W_o*h_{t-1} + b_o)
Nhận xét: 0 ; b_f, b_i, b_o là các hệ số bias; hệ số W, U giống như trong bài RNN.
displaystyle tilde{c_t} = tanh(U_c*x_t + W_c*h_{t-1} + b_c) , bước này giống hệt như tính s_t trong RNN.
displaystyle c_t = f_t * c_{t-1} + i_t * tilde{c_t}, forget gate quyết định xem cần lấy bao nhiêu từ cell state trước và input gate sẽ quyết định lấy bao nhiêu từ input của state và hidden layer của layer trước.
displaystyle h_t = o_t * tanh(c_{t}), output gate quyết định xem cần lấy bao nhiêu từ cell state để trở thành output của hidden state. Ngoài ra h_t cũng được dùng để tính ra output y_t cho state t.
Xem thêm: Personal Pronouns Là Gì – Các Loại Pronoun, 1 Số Bài Tập Về Pronoun
Nhận xét: h_t, tilde{c_t} khá giống với RNN, nên model có short term memory. Trong khi đó c_t giống như một băng chuyền ở trên mô hình RNN vậy, thông tin nào cần quan trọng và dùng ở sau sẽ được gửi vào và dùng khi cần => có thể mang thông tin từ đi xa=> long term memory. Do đó mô hình LSTM có cả short term memory và long term memory.
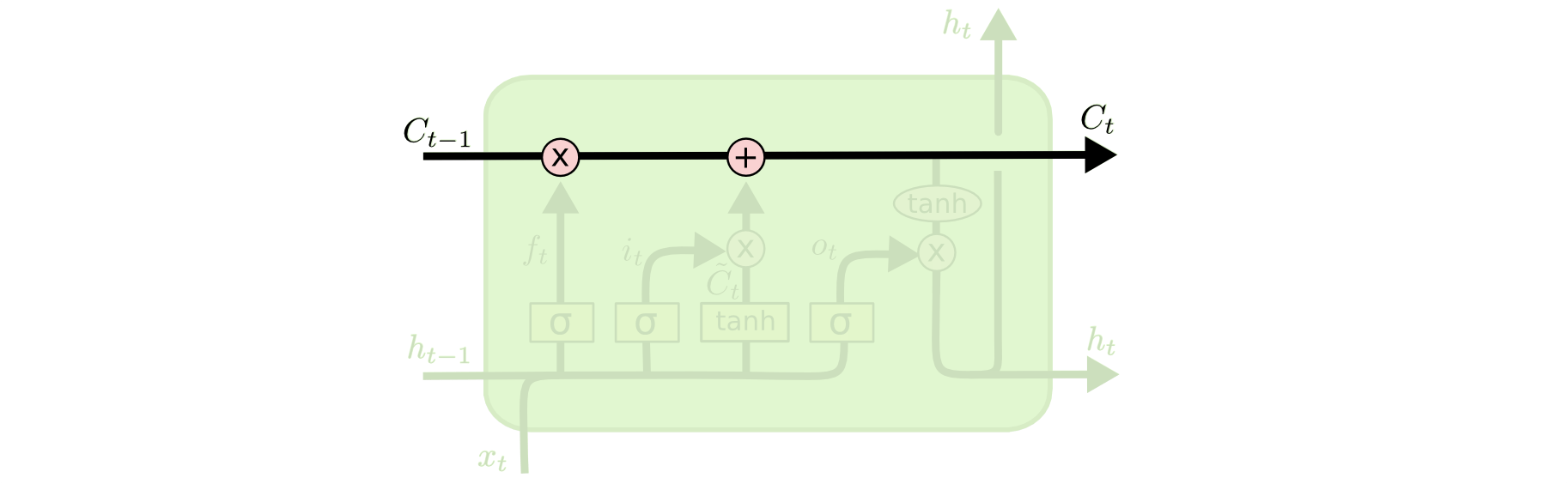
cell state trong LSTM
LSTM chống vanishing gradient
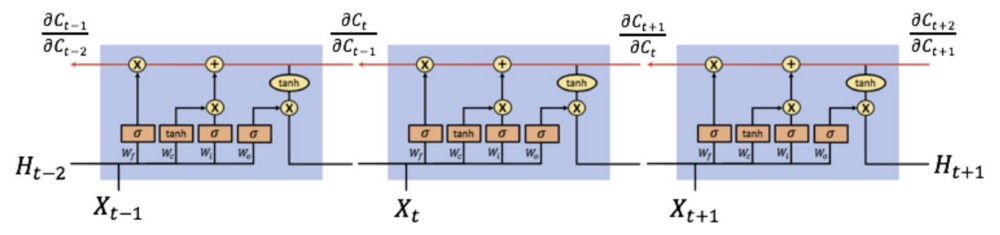
Ta cũng áp dụng thuật toán back propagation through time cho LSTM tương tự như RNN.
Thành phần chính gây là vanishing gradient trong RNN là displaystyle frac{partial s_{t+1}}{partial s_t} = (1-s_{t}^2) * W , trong đó s_t, W .
Tương tự trong LSTM ta quan tâm đến displaystyle frac{partial c_t}{partial c_{t-1}} =f_t. Do 0 nên về cơ bản thì LSTM vẫn bị vanishing gradient nhưng bị ít hơn so với RNN. Hơn thế nữa, khi mang thông tin trên cell state thì ít khi cần phải quên giá trị cell cũ, nên f_t approx 1 => Tránh được vanishing gradient.
Xem thêm: Narcissism Là Gì – Rối Loạn Nhân Cách Ái Kỷ
Do đó LSTM được dùng phổ biến hơn RNN cho các toán thông tin dạng chuỗi. Bài sau mình sẽ giới thiệu về ứng dụng LSTM cho image captioning.
Chuyên mục: Hỏi Đáp