Khi đụng đến machine learning thì chắc hẳn ai cũng nghe đến Linear Regression. Mình cũng vừa mới tìm hiểu sơ qua mô hình này. Nếu thực thi bài toán dự đoán với mô hình này bằng các ngôn ngữ như R, Python thì đã có sẵn plugin rồi, bạn chỉ cần học cách sử dụng plugin, input, output như thế nào là ok.
Bạn đang xem: Linear regression là gì
Trong bài viết này, mình không chia sẻ về cách sử dụng plugin, mà thay vào đó mình sẽ chia sẻ về thuật toán mà Linear Regression đã sử dụng. Bài viết chỉ ở mức cơ bản, không khai thác quá sau về các chứng minh tại sao lại có công thức như vậy :)) cái này các bạn có thể tìm đọc trên wiki.
Trong bài viết này mình có sử dụng một số ảnh từ nguồn https://towardsdatascience.com/
Bài viết bao gồm:
Bài toánCông thức vẽ đường thẳngHàm LossGradient descentCode demoTham khảo
1| BÀI TOÁN
Linear Regression là bài toán tìm đường thẳng đi qua các điểm sao cho khoản cách từ các điểm đến đường thẳng là nhỏ nhất.

Ví dụ ta có bài toán như hình trên. Hình bên trái là tập hợp các điểm khi biết x và y. Hình bên phải có thêm đường thẳng màu đỏ đi qua các điểm sao cho khoản các từ các điểm xanh đến đường màu đỏ là nhỏ nhất. Như vậy chốt lại mục đích của ta là đi tìm đường màu đỏ.
Vậy làm sao để tìm được đường màu đỏ?
Nếu nhìn bằng mắt và vẽ bằng tay, bạn cầm thước lên và vẽ vẽ vài đường xuyên qua tập hợp điểm đó thì khá dễ dàng. Nhưng nếu giờ muốn máy tính làm giúp thì máy tính sẽ không biết bắt đầu từ đâu, vẽ từ đâu.

Như hình trên, bạn có thể vẽ tay bằng thước được vài ba đường xanh, đỏ, vàng kia. Nhưng rồi thêm một câu hỏi lại đặt ra, làm sao biết được đường nào là chuẩn nhất?
Để biết đường nào chuẩn nhất thì phải trả lời đường nào có khoản cách đến các điểm là nhỏ nhất thì là chuẩn nhất.
Vậy tiếp câu hỏi nữa là làm sao để tính được khoản cách từ đường thẳng đến các điểm là nhỏ nhất?
Dễ ẹc, đo thôi, lấy thước đo :))

Nhưng 1, 2, 3 điểm thì còn đo được. Chứ triệu điểm rồi sao đo. Phải nhờ đến máy thôi.
Vậy chốt lại mình sẽ nhờ máy làm giúp mình 2 việc:
Tìm đường thẳng đi qua các điểm.Tính xem khoản cách từ cái đường vừa tìm được ở bước 1 đó có khoản cách đến các điểm là bao nhiêu. Nếu khoản cách quá lớn, thì quay lại bước 1 là tìm đường khác rồi lại qua bước 2 tính xem độ xa là bao nhiêu và cứ thế loop đến khi tìm được đường thẳng chuẩn.

Quay lại khái niệm một xíu. Tại sao chúng ta lại phải đi tìm đường thẳng chi vậy???
Các điểm màu xanh đó là dữ liệu ban đầu mà ta có. Tức là ban đầu ta biết X là bao nhiêu, Y là bao nhiêu, sau đó từ trục tung và hoành ta vẽ được các điểm xanh đấy.
Thế rồi một ngày nọ, ta được cho 1 con số X=*&*
gì đó, hỏi Y là bao nhiêu? Điểm mới đó sẽ nằm đâu trên đồ thị?
Muốn biết điểm mới đó sẽ nằm đâu thì phải biết Y. Muốn biết Y thì cần có một đường thẳng chuẩn, đường đó giao với đường thẳng vẽ lên từ X sẽ ra được Y.

Ví dụ như hình trên, cho X = 0.6, nhờ đường màu đỏ, ta suy ra đường Y = 4.2.
Đây cũng là bài toán thực tế. Ví dụ như bài toán dự đoán giá nhà. X sẽ là tuổi thọ căn nhà, Y là giá nhà. Ban đầu có vài căn nhà đã được báo giá như:
Căn A: tuổi thọ là 2 năm nên có giá là 5 tỷCăn B: tuổi thọ là 3 năm nên có giá là 3 tỷCăn C: tuổi thọ là 5 năm nên có giá là 1 tỷ
Vậy hỏi nếu có căn D với tuổi thọ là 2.5năm (X=2.5) thì giá (Y) tầm bao nhiêu???
2| Công thức vẽ đường thẳng
Trên là công thức chung để vẽ đường đi qua các điểm sẽ có dạng đường thẳng, hay đường hơi cong cong tuỳ theo hàm mũ bao nhiêu.
Về cơ bản, nếu là đường thẳng thì chỉ cần hàm bật nhất (Y = heta_0+ heta_1x)
Ví dụ với Y = 3 + 2x thì:
| 1 | 5 |
| 2 | 7 |
| 4 | 11 |
3| Hàm Loss
Hàm này còn có tên gọi khác là Cost hay Error.
Xem thêm: Resin Là Gì – đặc điểm
Đây là hàm sẽ giúp mình tính sai số giữa đường thẳng và các điểm.

Hàm Loss sẽ có công thức tính như sau:
}^2=frac{1}{2M}sum_{i=1}^M{}^2>
Trong đó, h(x) sẽ là:

Lúc này, các bạn có thấy h(x) nhìn quen không? Nó là hàm tính Y dự đoán.Còn y trong công thức L(x,y,????) là y thực tế trong tập data ban đầu (y thực tế). M là tổng số phần tử X.
Ví dụ:Ban đầu ta có tập dữ liệu với X và Y ban đầu.Cho sẵn công thức tính đường thẳng là Y = 3 + 2x. Sau đó dựa vào công thức tính Y đó ta tính Y dự đoán.Tiếp đến lấy Y dự đoán – Y ban đầu để tính sai số giữa y thực tế với y dự đoán là bao nhiêu.
| 1 | 6 | 3 + 2*1 = 5 | 5 – 6 = -1 | 1 | |
| 2 | 6 | 3 + 2*2 = 7 | 7- 6 = 1 | 1 | |
| 4 | 9 | 3 + 2*4 = 11 | 11 – 9 = 2 | 4 | |
| M = 3 | sum(1,1,4) = 6 | (frac{1}{2*3}*6 = 1) |
Như vậy, hàm Loss = 1. Kết quả là 1 có vẻ khá lý tưởng. Nhưng nếu tìm được đường thẳng khác làm cho Loss càng min, tức càng tiến về 0 là càng tốt.
Bây giờ thử đổi ( heta_0 = 2), như vậy công thức mình sẽ có là Y =2 + 2x thì ta sẽ có Loss như sau:
| 1 | 6 | 2 + 2*1 = 4 | 4 – 6 = -2 | 4 | |
| 2 | 6 | 2 + 2*2 = 6 | 6 – 6 = 0 | 0 | |
| 4 | 9 | 2 + 2*4 = 10 | 10 – 9 = 1 | 1 | |
| M = 3 | sum(4,0,1) = 5 | (frac{1}{2*3}*5 = 0.83) |
Sau khi thử 2 công thức Y ta có kết quả sau:
Với Y = 3 + 2x thì Loss = 1Với Y = 2 + 2x thì Loss = 0.83
Như vậy công thức đường thẳng Y = 2x + 2 có vẻ tốt hơn.Vậy để làm sao biết cách điều chỉnh số ( heta_0) và ( heta_1) để có được công thức vẽ đường thẳng chuẩn???
Chính vì vậy phải nhờ đến thuật toán Gradient descent.
4| Gradient descent
Gradient descent dịch qua tiếng việt là xuống dốc. Hay nói cách khác là hàm giúp ta tìm được những ( heta) mới, giúp cho hàm Loss càng tiến về min.

Hàm sẽ có công thức như sau:
Trong đó:
( heta_n): là theta mới( heta_o): là theta cũ trước đó(alpha): là learning rate. Để dễ hiểu hơn bạn có thể hình dung nó như độ dài cho mỗi bước chân khi xuống dốc. Đây là con số bạn tự định nghĩa. Nếu (alpha) quá lớn thì bước chân dễ bị trượt quá khỏi điểm min và đi luôn về vùng xa xâm. Nếu (alpha) quá nhỏ thì tốc độ xuống dốc của bạn hơi lâu.

(frac {partial{L(x,y, heta)}}{partial{ heta}}): sẽ có công thức tính như sau:
{x^{(i)}}^j>
Hay viết cách khác dễ hiểu cho ( heta_0) mới và ( heta_1) mới:

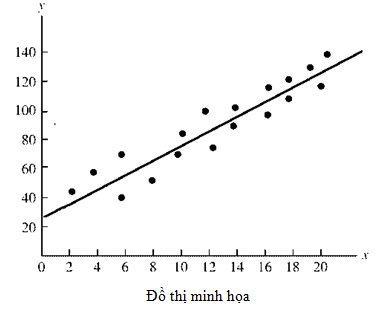
5| Code demo
Bài toán ví dụ ở đây sẽ là cho tập hợp các điểm biết x và y. Tìm đường thẳng đi qua các điểm trên sao cho khoản cách từ các điểm đến đường thẳng là nhỏ nhất.
Điểm 1: x = 2 và y = 2Điểm 2: x = 7 và y = 4Điểm 3: x = 10 và y = 6
Bắt đầu mổ xẻ bài toán thoy.
Công thức vẽ đường thẳng sẽ là (Y = heta_0 + heta_1x). Như vậy ta có:
(2 = heta_0 + heta_1*2)(4 = heta_0 + heta_1*7)(6 = heta_0 + heta_1*10)
Mục tiêu sẽ đi tìm ( heta_0) và ( heta_1) – dùng thuật toán grdient descent. Tiếp đó tính Loss để đánh giá xem ( heta_0) và ( heta_1) đó có phải là tốt nhất không? Nếu không tốt lại quay lại tìm ( heta_0) và ( heta_1) khác.
Đầu tiên, vì không biết cần bắt đầu từ đâu,nên ta gán ( heta_0) và ( heta_1) là zero: ( heta_0 = 0) và ( heta_1 = 0)Như vậy ta có công thức tính đường thẳng là Y = 0 + 0x
| 2 | 2 | 0 | -2 | 4 | |
| 7 | 4 | 0 | -4 | 16 | |
| 10 | 6 | 0 | -6 | 36 | |
| m = 3 | sum(4,16,36) = 56 | (1/2*3) * 56 = 9.33 |
Với Y = 0 + 0x thì Loss = 9.33 con số này khá cao. Nên ta thử tính a mới và b mới xem Loss có giảm không.Ở ví dụ này mình lấy ???? = 0.001
Tính ( heta_0) mới:
| 2 | 2 | 0*2 + 0 = 0 | 0 – 2 = -2 | |
| 7 | 4 | 0*7 + 0 = 0 | 0 – 4 = -4 | |
| 10 | 6 | 0*10 + 0 = 0 | 0 – 6 = -6 | |
| m = 3 | sum = -2 + -4 + -6 = -12 | ( heta_0= heta_0 – alphafrac{1}{3}(-12))(= heta_0-alpha(-4))(=0-0.001(-4))(=0.004) |
Tương tự tính b_new. Rồi tính Loss mới. Và vòng lặp cứ thế đến khi Loss → min là ok.
Xem thêm: Tổng Hợp Các Bài Hướng Dẫn Về Design Pattern Là Gì
Lười quá nên mình sẽ viết code để chạy :))
Import thư viện chia lấy dư và vẽ đồ thị để dùng như sau:
import matplotlib.pyplot as pltfrom __future__ import divisionViết hàm tính Y:
def computeY(theta, x): result = 0 for i in range(len(theta)): result = result + theta*(x**i) return resultViết hàm tình Loss:
}^2=frac{1}{2M}sum_{i=1}^M{}^2>
def computeLoss(X, _Y, theta): M = len(X) total = 0 for i in range(M): y = computeY(theta, X) diff = y – Y diff = diff**2 total = total + diff Loss = (1/(2*M))*total return LossViết hàm đệ quy tìm theta
def curve_fit(loop, theta, X, Y): M = len(X) # Tính Loss cho case đầu tiên với theta = zero L = computeLoss(X, Y, theta) print(“Case = 0 L=%.6f || theta0 = %.3f , theta1 = %.3f” %(L, theta, theta)) display_step = 5 # biến này chỉ phục vụ cho việc print kết quả for case in range(loop): # tính y dự đoán với theta Y_pred = for i in range(len(X)): Y_pred.append(computeY(theta, X)) # tính loss function L = computeLoss(X, Y, theta) # print thông tin với vẽ đồ thị if (case+1) % display_step == 0: print(“Case = %d L=%.6f || a = %.3f , b = %.3f” %(case+1, L, theta, theta)) plt.plot(X, Y, “r.”, label=”Training Points”) plt.plot( X, Y_pred, label = “Learned Theta curve”) # tìm theta mới for j in range(len(theta)): dlTmp = 0 for e in range(len(X)): _y = computeY(theta, X) dlTmp = dlTmp + (_y – Y)*(X**j) dl = (1/M)*dlTmp # alpha = 0.001 theta = theta – dl*0.001Khai báo biến và chạy
X = Y = theta = # khởi tạo theta ban đầu là zeroloop = 50 # lặp 50 lầncurve_fit(loop, theta, X, Y)Output:
Case = 0 L=9.333333 || theta0 = 0.000 , theta1 = 0.000Case = 5 L=6.135794 || theta0 = 0.015 , theta1 = 0.113Case = 10 L=3.647620 || theta0 = 0.030 , theta1 = 0.225Case = 15 L=2.184983 || theta0 = 0.041 , theta1 = 0.311Case = 20 L=1.325162 || theta0 = 0.050 , theta1 = 0.376Case = 25 L=0.819683 || theta0 = 0.057 , theta1 = 0.426Case = 30 L=0.522489 || theta0 = 0.063 , theta1 = 0.465Case = 35 L=0.347729 || theta0 = 0.068 , theta1 = 0.494Case = 40 L=0.244937 || theta0 = 0.071 , theta1 = 0.517Case = 45 L=0.184449 || theta0 = 0.074 , theta1 = 0.534Case = 50 L=0.148829 || theta0 = 0.077 , theta1 = 0.548

Nhìn vào output trên, ta thấy Loss ngày càng giảm với giá trị ( heta_0) mới và ( heta_1) mới.Nhìn vào đồ thị, thì đường thẳng dần dần tiến gần về 3 điểm màu đỏ.
Chuyên mục: Hỏi Đáp