Phương pháp rút trích đặc trưng hình ảnh HOG xuất bản ở hội nghị CVPR 2005 được đề xuất bởi tác giả là Dalal và Triggs. Bạn không nghe lầm đâu, năm 2005 đấy :D. Bài báo gốc HOG đề xuất phương pháp rút trích đặc trưng sử dụng các thống kê histogram về hướng trên ảnh gradient cho bài toán phát hiện người (human detection). CVPR là một trong những hội nghị thuộc hàng đỉnh của lĩnh vực thị giác máy tính. Do đó, bài báo HOG này xuất hiện ở đó quả thật là một điều gì đó không phải là ngẫu nhiên. Mặc dù bài toán phát hiện người với những phương pháp hiện đại trong học sâu đã cho ra kết quả tốt vượt bậc đánh bại các phương pháp truyền thống. Nhưng không phải vì vậy mà mình “được phép” nhảy cóc bỏ qua những phương pháp xử lý truyền thống, đây là quan điểm cá nhân của mình.
Bạn đang xem: Hog là gì
Link bài báo gốc: http://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
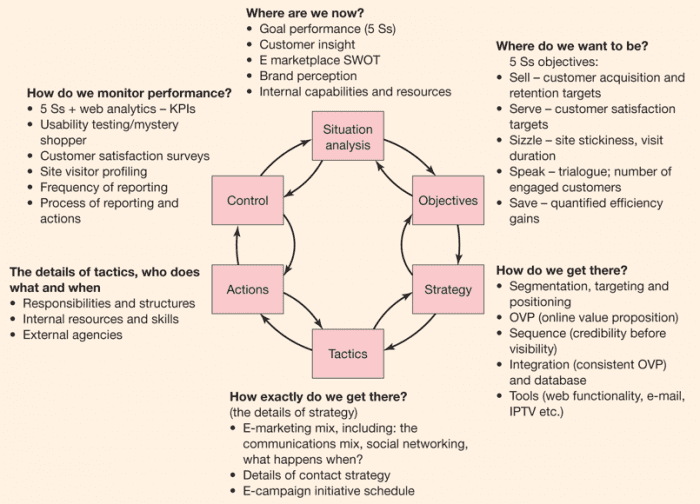
Rút trích đặc trưng hình ảnh nằm ở bước nào để giải bài toán phát hiện đối tượng? Rồi, mình sẽ nêu luồng hoạt động cơ bản của các giải thuật phát hiện đối tượng:
Đọc ảnhTiền xử lý (preprocessing): hình ảnh được đưa qua bước tiền xử lý để thực hiện các thao tác như cân bằng sáng, làm mờ, …Trích đặc trưng ảnh (feature extraction): bằng cách sử dụng các phương pháp rút trích đặc trưng ảnh ta sẽ thu được vector đặc trưng của ảnh. Nói một cách nôm na thân quen đó chính là bạn mã hóa hình ảnh thành một vector, và vector này mang những đặc trưng (các số thực) đại diện cho ảnh đó.Huấn luyện mô hình học máy (training): với phương pháp truyền thống, ta thường sử dụng mô hình SVM trong machine learning để phân tách các vector đặc trưng thành các lớp cần phân loại.Kiểm thử (validation): sau khi huấn luyện xong mô hình học máy bạn cần phải đánh giá mô hình mình đã huấn luyện đạt độ chính xác là bao nhiêu phần trăm trên tập kiểm thử này. Khi bạn đã hài lòng với kết quả kiểm thử, ta có thể dừng quá trình huấn luyện.
Đấy!! Trích đặc trưng ảnh nằm ở bước số 2. Đặc trưng hình ảnh rút trích có tốt hay không sẽ ảnh hưởng đến kết quả của độ chính xác. Vì vậy, ở các phương pháp truyền thống, họ đưa ra các thiết kế nhằm cố gắng rút trích thông tin hình ảnh một cách tốt nhất.
Sau khi huấn luyện xong mô hình SVM, quá trình kiểm tra (testing) sẽ thay đổi một chút ở bước 3 và bước 4. Cụ thể là ta dùng các trọng số của SVM đã tính toán được để tiến hành phân lớp, chứ không phải cần tối ưu hóa các trọng số này như trong quá trình huấn luyện. Bước 4 là ta sẽ đánh giá kết quả dự đoán bằng định tính (xem bằng mắt coi nó phát hiện đối tượng có hợp lý không) hoặc định lượng (cân đo đong đếm % độ chính xác).
Hiện thực giải thuật HOG

(nguồn ảnh: bài báo gốc HOG)
Mình sẽ đi chi tiết từng bước 1 nhé. Ở mỗi bước mình sẽ minh họa những script ngắn, còn code HOG dùng được sẽ post ở cuối bài viết này. Tại thời điểm viết code cho bài viết ngay lúc này, mình đang tham khảo bài báo gốc của tác giả để hiện thực. Vì vậy, mọi người hãy cố gắng rèn luyện những kỹ năng để đọc hiểu paper nước ngoài nhé, nhất là Tiếng Anh và kiến thức nền tảng Xử lý ảnh.
1. Chuẩn hóa mức sáng và màu sắc của ảnh
Việc dùng ảnh màu và các chuẩn hóa trên ảnh cho kết quả tốt hơn ảnh xám khoảng 1.5%. Thôi, ta là dân newbie mới học, khó quóa bỏ qua nhe. Đọc ảnh xám cho gọn nhẹ nè :x. Ảnh đầu vô kích thước 64×128 (w x h) pixels.
2. Tính gradient của ảnh
Có nhiều cách đạo hàm ảnh để tính gradient như Laplacian, Sobel. Ủa ủa, sao chữ gradient quen quá vậy ta :D, thì ra là ở đây Gradient của ảnh là gì?. Chém chuối vậy thoai, chớ mình dùng filter 1-D đơn giản (-1, 0, 1) để convolution tính ảnh đạo hàm theo trục x, và chuyển vị của filter trên để tính ảnh đạo hàm theo trục y.
# gradientxkernel = np.array(>)ykernel = np.array(, , >)dx = cv2.filter2D(img, cv2.CV_32F, xkernel)dy = cv2.filter2D(img, cv2.CV_32F, ykernel)
3. Vote hướng vào cell (histogram)
Cái đệch! Tiêu đề Vinglish vậy, thế sao chơi :(. Cứ bình tĩnh nào, để Minh giải thích từng cái một.
Xem thêm: Nhiệt Dung Riêng Là Gì, Nhiệt Dung Riêng Của Nước
Ở bước 2, ta đã tính được ảnh gradient theo trục x (dx) và gradient theo trục y (dy). Kích thước dx và dy đều bằng ảnh gốc, tức 64×128. Tưởng tượng rằng dx và dy là 2 tờ giấy hình chữ nhật có cùng kích thước, và bạn lấy 2 tờ giấy chồng lên nhau. Như vậy thì mỗi pixel trên dx sẽ ứng với 1 pixel ở tọa độ tương ứng trên dy. Vì vậy, với cặp giá trị này ta sẽ tính được góc và biên độ tại pixel đang xét!

(nguồn ảnh: https://www.onlinemathlearning.com/vector-magnitude.html)
Nhìn hình ta có:
Góc (hay nói cách khác là hướng) = arctan(y/x)Độ lớn (biên độ) = sqrt(x * x + y * y)
Giờ đây ta có thêm một khái niệm mới chen chân vô đó là cell (dịch: ô). Một cell được thiết kế là có kích thước 8×8 pixel (đây là siêu tham số, tác giả có tùy chỉnh và chọn 8 là giá trị hợp lý qua các thí nghiệm). Do đó ảnh đầu 64×128 thì sẽ có 8×16 = 128 cell cả thảy (8 ô ngang và 16 ô dọc).
Tiếp đến, ta xét lần lượt mỗi cell. Nhắc lại, một cell kích thước 8×8 vì vậy ta có 64 giá trị hướng và 64 giá trị biên độ trong cell đó. Ta sẽ tiến hành vote (dịch: bầu cử) hướng vào các lựa chọn góc nằm từ 0-180 độ (các góc giá trị âm sẽ được lấy trị tuyệt đối quy về 0-180 luôn). Trong cung tròn 0-180 độ này, ta chia chúng thành các 9 đoạn rời rạc (9 bin). Nếu hướng thuộc khúc nào thì ta vote vào bin đó. Quá trình vote này gọi là tính toán / thống kê Histogram.
Cụ thể:
Hướng 0-20 độ: ta sẽ vote hướng thuộc đoạn này vào bin 0Hướng 20-40 độ: bin 1Hướng 40-60 độ: bin 2Hướng 60-80 độ: bin 3Hướng 80-100 độ: bin 4Hướng 100-120 độ: bin 5Hướng 120-140 độ: bin 6Hướng 140-160 độ: bin 7Hướng 160-180 độ: bin 8
Khi có hướng rơi vào bin, ta không vote kiểu bình thường là giá trị trong bin tăng lên 1 đơn vị, mà ta sẽ tăng lên một giá trị bằng biên độ của hướng đó. Ví dụ: hướng 42 độ, biên độ 0.27 => vote vào bin 2, giá trị bin 2 += 0.27. Hướng của các pixel trong cell vote vào bin nào thì giá trị bin đó tăng dần lên.
Sau khi vote xong, ta có 8×16 cell, mỗi cell có 9 bin.
# histogrammagnitude = np.sqrt(np.square(dx) + np.square(dy))orientation = np.arctan(np.divide(dy, dx+0.00001)) # radianorientation = np.degrees(orientation) # -90 -> 90orientation += 90 # 0 -> 180num_cell_x = w // cell_size # 8num_cell_y = h // cell_size # 16hist_tensor = np.zeros() # 16 x 8 x 9for cx in range(num_cell_x): for cy in range(num_cell_y): ori = orientation mag = magnitude # https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html hist, _ = np.histogram(ori, bins=bins, range=(0, 180), weights=mag) # 1-D vector, 9 elements hist_tensor = hist passpass
4. Chuẩn hóa theo block
Tại sao ta cần phải chuẩn hóa ở bước này? Vì hiện tại mỗi cell đang mang trong mình histogram trên vùng ảnh 8×8, các thông tin này mang tính chất cục bộ. Vì vậy tác giả đã đưa ra nhiều cách chuẩn hóa khác nhau dựa trên các khối (block) chồng lấn (overlap) nhau.
Đến đây ta cần biết 1 block là gì. Một block gồm nhiều cell, block 2×2 nghĩa là ta có vùng diện tích của 4 cell liền kề –> block này sẽ phủ trên diện tích = 16×16 pixel. Trong quá trình chuẩn hóa, ta sẽ lần lượt chuẩn hóa block 2×2 đầu tiên, rồi dịch block đó sang 1 cell và cũng thực hiện chuẩn hóa cho block này. Như vậy, giữa block đầu tiên và block liền kề đã có sự chồng lấn cell lẫn nhau (2 cell), trong tiếng Anh người ta dùng từ overlap.
Xem thêm: Chạy Bộ Tiếng Anh Là Gì ? Từ Vựng Tiếng Anh Về Các Môn Thể Thao

(nguồn ảnh: https://www.learnopencv.com/histogram-of-oriented-gradients/)
Thao tác cụ thể chuẩn hóa cho mỗi block Minh sẽ dùng L2-Norm (cho dễ hiện thực, ahihi). Cách làm là mình lấy tất cả vector của 4 cell trong block đang xét nối lại với nhau thành vector v. Vector v có 9 x 4 = 36 phần tử. Sau đó ta chuẩn hóa (tính toán lại vector v) theo công thức bên bên dưới:

(nguồn ảnh: bài báo gốc HOG)
Bản chất của chuẩn hóa L1-norm, L2-norm đó là:
L1-norm: sau chuẩn hóa, tổng các giá trị của những phần tử trong vector bằng 1.L2-norm: sau chuẩn hóa, độ dài vector bằng 1.
# normalizationredundant_cell = block_size-1feature_tensor = np.zeros()for bx in range(num_cell_x-redundant_cell): # 7 for by in range(num_cell_y-redundant_cell): # 15 by_from = by by_to = by+block_size bx_from = bx bx_to = bx+block_size v = hist_tensor.flatten() # to 1-D array (vector) feature_tensor = v / LA.norm(v, 2)
5. Trích vector đặc trưng của các block đã chuẩn hóa cho ảnh 64×128
Đến đây coi như xong rồi á. Block kích thước 2×2 chuẩn hóa trên các block overlap, như vậy tổng cộng ta sẽ có 7×15 block cả thảy. Mỗi block mang trong mình 4 cell (2×2), mỗi cell có 9 bin. Từ đó, nếu ta phẳng hóa toàn bộ đặc trưng của tất cả các block có trên ảnh 64×128 ta sẽ được 1 vector đặc trưng có: 7 x 15 x 4 x 9 = 3780 phần tử!
import osimport cv2import numpy as npfrom numpy import linalg as LAIMG = “person.jpg”def hog(img_gray, cell_size=8, block_size=2, bins=9): img = img_gray h, w = img.shape # 128, 64 # gradient xkernel = np.array(>) ykernel = np.array(, , >) dx = cv2.filter2D(img, cv2.CV_32F, xkernel) dy = cv2.filter2D(img, cv2.CV_32F, ykernel) # histogram magnitude = np.sqrt(np.square(dx) + np.square(dy)) orientation = np.arctan(np.divide(dy, dx+0.00001)) # radian orientation = np.degrees(orientation) # -90 -> 90 orientation += 90 # 0 -> 180 num_cell_x = w // cell_size # 8 num_cell_y = h // cell_size # 16 hist_tensor = np.zeros() # 16 x 8 x 9 for cx in range(num_cell_x): for cy in range(num_cell_y): ori = orientation mag = magnitude # https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html hist, _ = np.histogram(ori, bins=bins, range=(0, 180), weights=mag) # 1-D vector, 9 elements hist_tensor = hist pass pass # normalization redundant_cell = block_size-1 feature_tensor = np.zeros() for bx in range(num_cell_x-redundant_cell): # 7 for by in range(num_cell_y-redundant_cell): # 15 by_from = by by_to = by+block_size bx_from = bx bx_to = bx+block_size v = hist_tensor.flatten() # to 1-D array (vector) feature_tensor = v / LA.norm(v, 2) # avoid NaN: if np.isnan(feature_tensor).any(): # avoid NaN (zero division) feature_tensor = v return feature_tensor.flatten() # 3780 featuresdef main(img_path): img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) img = cv2.resize(src=img, dsize=(64, 128)) f = hog(img) print(“Extracted feature vector of %s. Shape:” % img_path) print(“Feature size:”, f.shape) print(“Features (HOG):”, f) passif __name__ == “__main__”: print(“Start running HOG on image
” + “x1b ” + “x1bperson.jpg (ảnh này đặt cạnh file hog.py, hoặc dùng ảnh khác của bạn có cùng tên file)
Chuyên mục: Hỏi Đáp