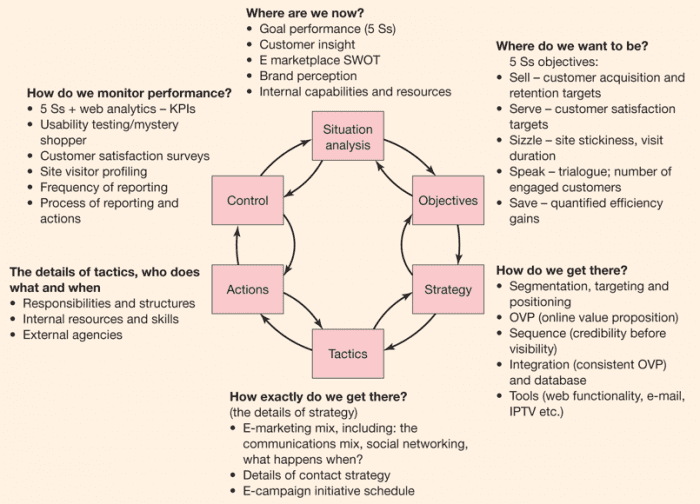
Như ở bài viết trước, mình đã trình bày với các bạn những điều cơ bản nhất về HDFS, và giờ với bài viết này mình sẽ trình bày với các bạn về Kiến trúc của HDFS.
Bạn đang xem: Hdfs là gì
I. Cơ chế Master – Slave
Như mình đã trình bày nhiều lần, HDFS sẽ chia nhỏ file của bạn thành các phần và lưu trữ chúng tại các máy trong cụm, và việc lưu trữ file sẽ tuân theo cơ chế Master – Slave.
Master – Slave ám chỉ mô hình có 1 ông chủ (master) cầm đầu một đám nô lệ (slave). Ông chủ sẽ không tham gia trực tiếp vào công việc, mà chỉ nắm giữ các đầu mục việc và thông tin của các nô lệ. Công việc chính của ông chủ là quản lý, giám sát để đám nô lệ để chúng làm việc đúng cách và đem lại hiệu quả.
Thật không ngờ máy tính cũng giai cấp
Cụ thể cơ chế master – slave được thể hiện trong HDFS bằng việc trong một cụm máy, sẽ chỉ bao gồm một máy duy nhất được gọi là là Namenode (Master) và các máy còn lại gọi là Datanode (Slave). Trong đó:
Datanode sẽ là nơi lưu trữ các file dữ liệu mà bạn đưa vào.Namenode là nơi lưu địa chỉ của file đó được chia và lưu trên các datanode nào.

Có một câu hỏi đặt ra là Tại sao Block trong HDFS có dung lượng cao tới vậy – 128M, trong khi block file system của Linux chỉ là 4KB?
Câu trả lời là: Big data là những tập dữ liệu rất lớn, đơn vị thuộc tầm Terabytes hay Petabytes. Vậy nếu kích thước của block mà nhỏ tầm 4KB thì một file dữ liệu đưa vào HDFS sẽ bị chia thành rất nhiều các block, điều này cũng là cho các file metadata ở namenode phình to hơn. Và đương nhiên điều này khiến việc quản lý metada khó khăn hơn, điều mà không ai muốn.
Xem thêm: Từ đơn Là Gì – Từ Phức Là Gì Ví Dụ Và Phân Biệt
IV. Cơ chế quản lý các bản sao
Một trong những đặc trưng của HDFS là có độ tin cậy cao và khả năng phục hồi sau lỗi tốt. Vậy HDFS đã làm thế nào để có được đăng trưng này? Giờ mình sẽ chỉ cho các bạn nhé.
Dữ liệu sau khi được chia thành các block, ngoài việc được lưu rải rác trên khắp các datanode, các block còn được nhân bản thành nhiều phiên bản khác nhau và lưu tại các datanode khác nhau. Bạn có thể xem hình ảnh dưới đây để hiểu rõ hơn.
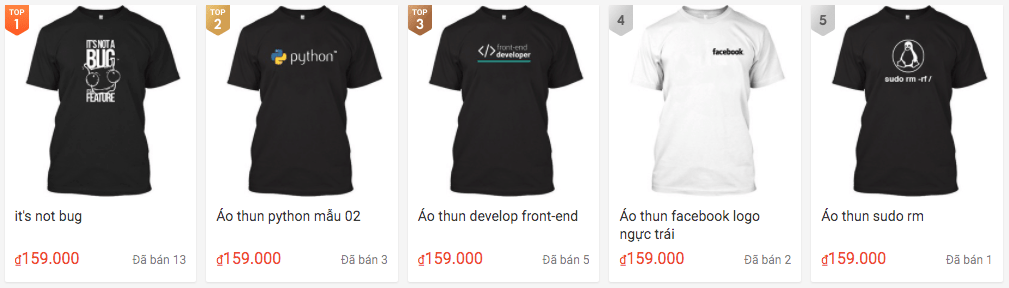
V. Tổng kết
Lại là một bài viết tràn ngập lý thuyết mà đọc xong có vẻ … chẳng hiểu gì và cũng chẳng giúp ích gì nhiều. Thật ra mình cũng từng vậy đấy, nhưng cứ đọc, đọng lại được trong đầu tý nào thì đọng, cái quan trọng nhất là mình cứ “biết nó là thế đã” còn nó quan trọng hay không thì sau này mới biết được. Nhưng mình tiết lộ luôn nhé, mình cảm thấy những kiến thức lý thuyết này rất bổ ích cho việc thực hành sau này đấy. Mấy nữa học tới đoạn thực hành với code, thử xem bạn có cảm giác giống mình không nhé.
Tóm tắt lại thì bài này có một số điều cần chú ý như sau:
Hadoop cluster hoạt động theo cơ chế master – slave.Một Hadoop cluster bao gồm 1 namenode và n datanode. Vì vậy namenode cần tính sẵn sàng cao, còn datanode thì không cần đề cao tính sẵn sàng.Namenode không phải là nơi trực tiếp lưu dữ liệu, mà chỉ là nơi lưu các metadata. Dữ liệu thực tế được chia thành các block và lưu tại các datanode.Các block sẽ được nhân bản và lưu trữ tại nhiều datanode khác nhau.
Xem thêm: Bánh Hỏi Tiếng Anh Là Gì, Bánh Hỏi
Chào tạm biệt, hẹn gặp lại ở bài viết kế tiếp.
Tương tác với HDFS thông qua restful api với WebHDFS… Còn nữa… mình đang viết
Chuyên mục: Hỏi Đáp