Logging là một công cụ đơn giản và mạnh mẽ, ghi lại toàn bộ những hoạt động của hệ thống.
Bạn đang xem: Elk là gì
Nhờ có logging, ta có thể tra cứu lại trạng thái của hệ thống trong quá khứ, những code nào đã được chạy, từ đó tìm ra lỗi và fix dễ dàng hơn.
Tuy nhiên việc tập chung và phân tích log của hệ thống là vấn đề khó khăn đối với mỗi doanh nghiệp. Hôm nay mình xin giới thiệu về ELK stack một công cụ mạnh mẽ dùng để quản lý và phân tích log tập chung.
Mục lục
1. Technical stack là gì?
2. ELK stack.
3. Các thành phần trong ELK stack.
4. Các trường hợp sử dụng ELK stack.
5. Vì sao nên sử dụng ELK stack.
1. Technical stack là gì?
Technical Stack, còn gọi là solution stack, là một tập hợp những phần mềm/công nghệ phối hợp chung với nhau, tạo thành một nền tảng để ứng dụng có thể hoạt động được.
Một stack thông thường sẽ được cấu tạo bởi các thành phần :
Hệ điều hành. Webserver. Database. Back-end Programming Language.
Mỗi thành phần trong stack đảm nhận một nhiệm vụ riêng biệt.
2. ELK stack.
ELK Stack là tập hợp 3 phần mềm đi chung với nhau, phục vụ cho công việc logging. Ba phần mềm này lần lượt là :
Elasticsearch: Cơ sở dữ liệu để lưu trữ, tìm kiếm và query log. Logstash: Tiếp nhận log từ nhiều nguồn, sau đó xử lý log và ghi dữ liệu vào Elasticsearch. Kibana: Giao diện để quản lý, thống kê log. Đọc thông tin từ Elasticsearch.
Điểm mạnh của ELK là khả năng thu thập, hiển thị, truy vấn theo thời gian thực. Có thể đáp ứng truy vấn một lượng dữ liệu cực lớn.
Hình dưới đây là cơ chế hoạt động của ELK stack :
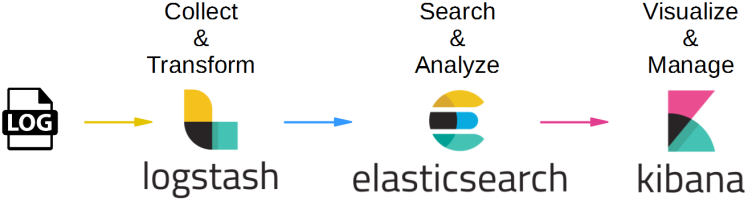
Đầu tiên, log sẽ được đưa đến Logstash. (Thông qua nhiều con đường, ví dụ như server gửi UDP request chứa log tới URL của Logstash, hoặc Beat đọc file log và gửi lên Logstash).
Logstash sẽ đọc những log này, thêm những thông tin như thời gian, IP, parse dữ liệu từ log (server nào, độ nghiêm trọng, nội dung log) ra, sau đó ghi xuống database là Elasticsearch.
Khi muốn xem log, người dùng vào URL của Kibana. Kibana sẽ đọc thông tin log trong Elasticsearch, hiển thị lên giao diện cho người dùng query và xử lý.
3. Các thành phần trong ELK stack.
3.1. Elasticsearch.
Elasticsearch là một RESTful distributed search engine. Hiểu nôm na là nó cung cấp khả năng tìm kiếm phân tán qua API. Lưu trữ dữ liệu theo dạng NoSQL database (cơ sở dữ liệu không có cấu trúc).
Elasticsearch cho phép bạn thực thi và kết hợp rất nhiều loại tìm kiếm: có cấu trúc, không cấu trúc, geo, metric theo cách bạn muốn.
Việc tìm kiếm trong một lượng ít dữ liệu rất dễ dàng, nhưng nếu có 1 tỷ dòng dữ liệu thì thế nào? Elasticsearch cho phép bạn có cái nhìn để khai thác khuynh hướng và các mẫu trong dữ liệu.
Elasticsearch rất nhanh, thực sự rất nhanh. Bạn có câu trả lời ngay tức thì với các dữ liệu thay đổi.
Xem thêm: Sửa Lỗi Sai Tiếng Anh, Ai Grammar Kiểm Tra Ngữ Pháp
Bạn có thể chạy nó trên hàng trăm server với hàng petabyte dữ liệu.
Vận hành dễ dàng:
Khả năng co giãn, Độ sẵn sàng cao. Dự đoán trước, tin cậy. Đơn giản, trong suốt
Elasticsearch sử dụng chuẩn RESTful APIs và JSON.
Như thế nào là một RESTful distributed search engine
Distributed and Highly Available Search Engine:
Mỗi Index là full shard với một số cấu hình của shard. Mỗi shard có một hoặc nhiều replica. Xử lý đọc và tìm kiến trên mõi replica shard.
Multi Tenant with Multi Types:
Hỗ trợ nhiều hơn một index. Hỗ trợ nhiều loại trên một index. Cấu hình index level (số shard, index storage).
Various set of APIs:
HTTP RESTful API. Native Java API. Tất cả API thực hiện thao tác node tự động mỗi khi định tuyến lại.
Document oriented:
Không cần định nghĩa trước schema. Schema có thể được định nghĩa cho mỗi loại tùy vào quá trình indexing.
Tin cậy.
Tìm kiếm (gần) theo thời gian thực.
Xây dựng dựa trên Lucene:
Mỗi shard là một Lucene index đầy đủ chức năng. Tất cả các ưu điểm của Lucene được khai phá thông qua cấu hình/plugin đơn giản.
Hoạt động nhất quán.
Open Source under the Apache License, version 2 (“ALv2”).
3.2. Logstash.
Logstash có chức năng phân tích cú pháp của các dòng dữ liệu. Việc phân tích làm cho dữ liệu đầu vào ở một dạng khó đọc, chưa có nhãn thành một dạng dữ liệu có cấu trúc, được gán nhãn.
Khi cấu hình Logstash luôn có 3 phần: Input, Filter, Output.
Bình thường khi làm việc với Logstash, sẽ phải làm việc với Filter nhiều nhất. Filter hiện tại sử dụng Grok để phân tích dữ liệu.
3.3. Kibana.
Kibana được phát triển riêng cho ứng dụng ELK, thực hiển chuyển đổi các truy vấn của người dùng thành câu truy vấn mà Elasticsearch có thể thực hiện được. Kết quả hiển thị bằng nhiều cách: theo các dạng biểu đồ.
4. Các trường hợp sử dụng ELK stack.
Với các hệ thống hoặc ứng dụng nhỏ, ta không cần sử dụng ELK stack làm gì, cứ dùng thư viện ghi log đi kèm với ngôn ngữ, sau đó ghi log ra file rồi đọc bình thường.
Tuy nhiên, với những hệ thống lớn nhiều người dùng, có nhiều service phân tán (microservice), có nhiều server chạy cùng lúc… thì việc ghi log xuống file không còn hiệu quả nữa. Lúc này số lượng máy chủ trên hệ thống là lớn và nhiều do đó chúng ta không thể dùng cách thủ công là remote vào từng máy rồi đọc log của từng server được, lúc này ELK stack sẽ giải quyết vấn đề đó. ELK stack sẽ ghi log tập chung vào một chỗ khiến chúng ta có thể dễ dàng quản lý log trên toàn hệ thống.
5. Vì sao nên sử dụng ELK stack.
Dễ tích hợp: Dù bạn có dùng Nginx hay Apache, dùng MSSQL, MongoDB hay Redis, Logstash đều có thể đọc hiểu và xử lý log của bạn nên việc tích hợp rất dễ dàng.
Hoàn toàn free: Chỉ cần tải về, setup và dùng, không tốn một đồng nào cả. Công ty tạo ra ELK Stack kiếm tiền bằng các dịch vụ cloud hoặc các sản phẩm premium phụ thêm.
Khả năng scale tốt: Logstash và Elasticsearch chạy trên nhiều node nên hệ thống ELK cực kì dễ scale. Khi có thêm service, thêm người dùng, muốn log nhiều hơn, bạn chỉ việc thêm node cho Logstash và Elasticsearch là xong.
Xem thêm: Sb Là Gì – #ask5 Les Là Gì, Sb, Fem Là Gì
Search và filter mạnh mẽ: Elasticsearch cho phép lưu trữ thông tin kiểu NoSQL, hỗ trợ luôn Full-Text Search nên việc query rất dễ dàng và mạnh mẽ.
Chuyên mục: Hỏi Đáp