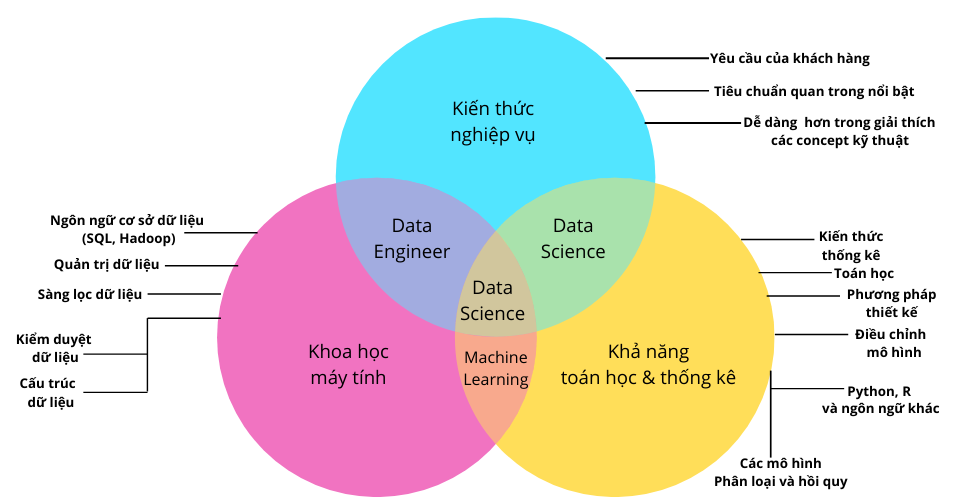
Data Scientist là nghề sexy nhất của thế kỉ 21, theo Harvard Business Review nhận định. Với skillset chuyên sâu và trải dài trên nhiều lĩnh vực, các Data Scientist (nhà khoa học dữ liệu) cũng được ví “quý hiếm như kỳ lân”.
Bạn đang xem: Data scientist là gì
Đọc bài phỏng vấn này của thienmaonline.vn với anh Nguyễn Hoàn, Data Scientist của Xomad, để biết.
Data Scientist là gì? Công việc cụ thể của họ?Những tố chất và kỹ năng cần thiết?Học gì để trở thành một Data Scientist?
Xem việc làm Data Scientist tại thienmaonline.vn
Tiểu sử:Nguyễn Hoàn tốt nghiệp Cử nhân tại ĐH KHTN TPHCM, chuyên ngành Software Engineering. Sau đó, anh học Thạc sĩ ngành Data Mining tại University of Trento, Ý. Năm 2013, Hoàn về nước, bắt đầu làm việc tại Sentifi với vị trí Data Scientist.
Hiện tại, anh Hoàn đang sống tại Pháp và làm việc từ xa (remotely) cũng với vị trí Data Scientist cho công ty Xomad có trụ sở tại LA, Mỹ.
Theo anh, Data Scientist là làm gì?
Data Scientist là người tạo ra giá trị từ data, với hai nhiệm vụ chính là:
Thu thập, xử lý dữ liệu để tìm ra những insight giá trị.
Ví dụ, dựa trên thông tin thu thập được từ các post/comment/status trên mạng xã hội, Data Scientist có thể tìm ra được: cứ gần đến ngày Valentine thì tần suất xuất hiện của thương hiệu ABC cao hơn hẳn.
Đây là một insight giá trị mà bộ phận Marketing có thể sử dụng cho các chiến dịch quảng cáo trong mùa Valentine.
Giải thích, trình bày những insight đó cho các bên liên quan, để chuyển hóa insight thành hành động.
Ví dụ, khi tìm ra được insight giá trị từ data, bạn cần làm report/presentation, hay visualization để biểu diễn, giải thích cho các bên liên quan hiểu được: 1)Insight đó là gì, có ý nghĩa gì? 2)Có thể ứng dụng cụ thể như thế nào để đem lại lợi ích cho doanh nghiệp/sản phẩm/người dùng.
Tuy nhiên, Data Scientist là nghề rất mới, nên định nghĩa về nó còn khá mơ hồ, nhập nhằng (ngay cả trên thế giới).Vì vậy, tùy theo từng công ty mà mô tả công việc, yêu cầu skillset, thậm chí job title có thể khác nhau đôi chút.
Anh Nguyễn Hoàn (ngoài cùng, bên phải) và đồng nghiệp
Sự khác biệt giữa Data Analyst và Data Scientist là gì?
Đúng là hai công việc này có trách nhiệm tương đối giống nhau. Ở một số công ty, Data Scientist có khi cũng là Data Analyst, hoặc thậm chí có thể nhập nhằng với cả Machine Learning Engineer, Data Engineer nữa.
Cá nhân mình thì nghĩ Data Scientist chia làm 2 dạng chính, tạm gọi nhánh A (Analysis) và nhánh B (Building), cụ thể:
Data Scientist nhánh A (Analysis) là những thinker. Nhiệm vụ chính của họ là phân tích dữ liệu bằng các phương pháp thống kê để tìm ra insight giá trị.
Data Scientist nhánh A cũng có thể gọi là Data Analyst.
Việc làm Data Analyst TPHCM
Việc làm Data Analyst Hà Nội
Data Scientist nhánh B (Building) thường mạnh về software engineering hơn. Họ đảm nhiệm việc xử lý/lưu trữ data, viết code/thuật toán cho các sản phẩm data của công ty.
Nếu cần một định nghĩa hẹp và cụ thể cho nghề Data Scientist, thì mô tả công việc của Data Scientist nhánh B sẽ chính xác hơn.
Bản thân mình thuộc về Data Scientist nhánh B, nên mọi chia sẻ cũng sẽ xoay quanh nhánh này.
Skillset của Data Scientist nhánh B
Khác biệt lớn nhất giữa hai nhánh A và B của Data Scientist là gì?
Như đã nói ở trên, Data Scientist nhánh B mạnh hơn về software engineering. Bởi vậy, trách nhiệm công việc chính của họ là xây dựng các sản phẩm data cho công ty.
Sản phẩm data cũng là một sản phẩm công nghệ phần mềm, song được xây dựng dựa trên dữ liệu.
Ví dụ, tính năng recommendation của Amazon là một sản phẩm data. Nó được xây dựng dựa trên nền tảng dữ liệu mà Amazon đã tích lũy được từ trước.
(Người dùng này đã mua những món đồ gì, có đặc điểm như thế nào, những món đồ tương tự, những món đồ nên mua kèm, những món đồ mà người dùng khác có hành vi tương tự đã mua.v.v…)
Sản phẩm data có thể là một sản phẩm riêng biệt, hoặc là một phần trong sản phẩm lớn hơn.
Ví dụ, tính năng recommendation là một sản phẩm data thuộc sản phẩm lớn là trang web Amazon.com.
Sản phẩm data bao gồm nhiều thành phần, nhưng luôn có cốt lõi là model (mô hình dữ liệu) được phát triển bằng machine learning.
Anh có thể giải thích cụ thể hơn về mô hình dữ liệu (model)?
Mình nói về machine learning (máy học) trước nhé!
Ví dụ, hãy hình dung nôm na “máy” ở đây là một cái hộp đen. Bạn muốn dùng cái hộp đen này để phân biệt hình ảnh con chó với con mèo. Vậy thì:
Bạn phải tìm rất nhiều hình ảnh của con chó, và hình ảnh của con mèo.Sau đó cho hộp đen đọc những hình ảnh này.Rồi dạy hộp đen: những đặc điểm nào trên bức hình sẽ cho biết đó là hình con chó, và những đặc điểm nào khác sẽ cho biết đó là hình con mèo.Cuối cùng, bạn đưa ra hai hình ảnh mới. Hộp đen sẽ nhận diện cho bạn đâu là hình con chó, đâu là hình con mèo dựa vào những gì nó đã được học.
Xem thêm: Tai Gem Club Danh Bai Doi Thuong, Tải Về Apk Gem Game Deluxe 1
Toàn bộ quá trình này gọi là máy học (machine learning). Còn cái hộp đen chính là một mô hình dữ liệu (data model).
Machine learning (máy học) là một lĩnh vực của trí tuệ nhân tạo, trong đó các thuật toán máy tính được sử dụng để tự học hỏi dựa trên dữ liệu đưa vào mà không cần phải được lập trình cụ thể.
Workflow của Data Scientist là gì?
Minh họa cho workflow của Data Scientist
Bước 1 – Input:
Workflow của Data Scientist bắt đầu với một nhu cầu/nhiệm vụ.
Ví dụ: nhu cầu tìm kiếm bằng hình ảnh của Google: đưa cho máy một bức ảnh, kết quả sẽ trả về những bức ảnh tương tự.
Nhu cầu này có thể bắt nguồn từ:
Do bộ phận business thu thập phản hồi của người dùng, và đề nghị có thêm tính năng ABC.Hoặc, do chính Data Scientist khi làm việc với dữ liệu, nghiên cứu đặc tính sản phẩm/công ty cũng như kiểu/lượng data hiện có… thì nảy ra sáng kiến phát triển thêm tính năng XYZ.
Bước 2 – Lên kế hoạch:
Sau khi xác định được nhu cầu/nhiệm vụ, Data Scientist sẽ họp và bàn bạc với bộ phận business cũng như các bên liên quan để xem xét:
Làm tính năng này có khả thi hay không?Sẽ cần loại dữ liệu gì? Tìm ở đâu? Bao nhiêu là đủ? Lấy dữ liệu về như thế nào?.v.v…Cần bao nhiêu resources (nhân lực, thời gian…)?Tính năng này sẽ được gắn vào đâu trong sản phẩm cuối cùng của công ty, sẽ giúp ích được gì cho người dùng..v.v…
Bước 3 – Thu thập và làm sạch dữ liệu:
Để dạy cho máy cách phân biệt con chó với con mèo chẳng hạn, thì phải cho nó học càng nhiều hình ảnh càng tốt. Nên phải đi gom dữ liệu.
Dữ liệu gom xong sẽ còn rất lộn xộn và nhiều rác, thì mình phải làm sạch dữ liệu. Hoặc nếu dữ liệu chưa đủ, thì phải kiếm thêm.
Ví dụ:
Có những hình mình không cần thì loại bỏ. Hình mình cần nhưng bị mờ thì làm cho nó rõ hơn. Hoặc hình thô (chưa gán nhãn) thì gán nhãn cho nó.
Cũng có thể tìm thêm nguồn dữ liệu được open source và đã gán nhãn sẵn.
Sau đó, phải đồng bộ hóa dữ liệu.
Ví dụ, hình ảnh gom về có nhiều kích thước khác nhau, thì phải đưa hết về cùng một kích thước hoặc định dạng, tùy theo mô hình mình chọn.
Bước 4 – Chọn giải pháp:
Nếu vấn đề đã có sẵn giải pháp
Thì lựa chọn/kết hợp các giải pháp lại (vd: chọn thuật toán ABC hoặc XYZ), chạy thử nghiệm, kiểm tra xem thử nghiệm nào là tốt nhất và vì sao, tiếp theo sẽ chọn giải pháp nào để phát triển thêm .v.v…
Nếu vấn đề chưa có sẵn giải pháp
Thì cần làm research: tìm hiểu xem trước mình, đã có ai từng làm về vấn đề này chưa, giải pháp của họ là gì, có khả thi không, liệu giải pháp nào tốt hơn .v.v…
Sau đó, chọn ra một hoặc một loạt phương pháp để thử nghiệm giống như ở trên.
Bước 5 – Machine learning (máy học):
Sau khi đã chọn được giải pháp, thì cần dành thời gian cho máy học.
Tùy theo model là gì, sử dụng công cụ nào, hệ thống công ty đã có sẵn những gì .v.v… mà mình sẽ cho model chạy qua chương trình, rồi điều chỉnh để kiểm soát performance đầu ra của model đó.
Khi train một model, hãy tưởng tượng giống như bạn có một bảng điều khiển với rất nhiều nút vậy. Bạn thử chỉnh cái nút này một chút, thấy kết quả ra tốt hơn chút xíu thì giữ lại, rồi thử chỉnh nút khác.
Cứ như vậy, cho đến khi ra được kết quả tốt nhất.
Ví dụ, có rất nhiều yếu tố để phân biệt con chó với con mèo.
Tùy bạn điều chỉnh để máy tập trung vào dấu hiệu nào nhiều hơn (cái mõm/những vùng có vẻ cái mõm, màu lông .v.v…) Nó sẽ ưu tiên các dấu hiệu đó để nhận diện đúng hơn.
Bước 6 – Output:
Output công việc của Data Scientist là một model như đã giới thiệu ở trên. Sau đó, thông thường, model này sẽ được gắn vào một sản phẩm lớn.
Ví dụ: model để gợi ý mua hàng của trang web Amazon.
Đôi khi, nếu model là một giải pháp/phát kiến mới, thì bộ phận Data Science của công ty bạn sẽ có nhiệm vụ viết bài báo hoặc tổ chức hội thảo khoa học để công bố kết quả nghiên cứu.
Tuy nhiên, chỉ một vài công ty lớn như Facebook, Google… có bộ phận chuyên nghiên cứu về Data Science.
Xem thêm: Corporate social responsibility là gì
Và trên thực tế, cũng rất hiếm có phát kiến mới có thể áp dụng thực tiễn. Vì rất nhiều khi, bạn tạo ra được một mô hình tốt, chính xác song lại chạy quá chậm, quá tốn tài nguyên thì cũng không đưa vào sử dụng được.
Chuyên mục: Hỏi Đáp