Clustered index là loại index theo đó các bản ghi trong bảng được sắp thứ tự theo trường index. Khi bảng được tạo clustered index thì bản thân nó trở thành một cây index, với các node lá chứa khóa là các trường được index và cũng đồng thời chứa tất cả các trường còn lại của bảng. Vì các bản ghi chỉ có thể được sắp xếp trên cây index theo một thứ tự nhất định nên mỗi bảng chỉ có thể có tối đa một clustered index. Bạn tạo clustered index như sau:
Khi bảng đã có clustered index thì các index khác (nonclustered) sẽ dùng khóa của trường clustered index làm con trỏ để trỏ về bản ghi tương ứng (nếu bảng không có clustered index thì một giá trị RID nội bộ được dùng).
Bạn đang xem: Clustered index là gì
Clustered index không đòi hỏi phải duy nhất (unique). Nhưng khi nó không duy nhất thì khóa index được gắn thêm một giá trị 4-byte ngẫu nhiên để đảm bảo các node index vẫn là duy nhất. Mục đích của việc này là để cho con trỏ trong các index khác luôn trỏ đến đến duy nhất một bản ghi, khi đó con trỏ sẽ bao gồm khóa index + chuỗi 4 byte được gắn thêm.
Việc gắn thêm như vậy làm tăng kích thước của clustered index cũng như các index khác, nên trong đa số tình huống thực tiễn bạn nên tạo clustered index là duy nhất. Thực tế, theo mặc định một clustered index duy nhất sẽ được tạo khi khai báo khóa chính.
Xem thêm: Phobia Là Gì – Các Từ Chỉ Tên Các Nỗi Sợ
Việc tìm kiếm theo trường có clustered index tối ưu hơn so với non-clustered index vì nó bỏ qua được bước bookmark lookup (do tất cả các trường dữ liệu đã có sẵn tại node index). Ta hãy so sánh hiệu năng của hai loại index thông qua một ví dụ: bảng Customer vốn đã có clustered index trên trường CustomerID; giờ ta hãy copy dữ liệu sang một bảng mới và tạo non-clustered index cho CustomerID; sau đó thực hiện cùng một câu lệnh trên hai bảng.
USE AdventureWorks GO SELECT * INTO Sales.Customer_NC FROM Sales.Customer GO CREATE INDEX Idx_CustomerID_NC ON Sales.Customer_NC ( CustomerID) GO — #1 SELECT CustomerID,CustomerType FROM Sales.Customer WHERE CustomerID = 27684 — #2 SELECT CustomerID,CustomerType FROM Sales.Customer_NC WHERE CustomerID = 27684
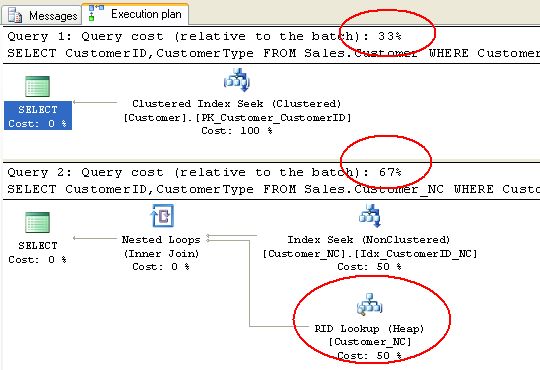
Như phương án thực thi cho thấy, câu lệnh thứ nhất (có clustered index) chỉ có chi phí bằng một nửa so với câu lệnh thứ hai (nonclustered index), do câu lệnh thứ hai cần thêm thao tác bookmark lookup (RID lookup ở trong hình). Bạn có thể hình dung clustered index là một covering index với độ bao phủ là toàn bộ các cột trong bảng, nhưng không chiếm thêm không gian lưu trữ riêng cho index.
Xem thêm: Experiment Là Gì – Nghĩa Của Từ Experiment
Cũng vì dữ liệu được lưu cùng với node index nên các lệnh tìm kiếm theo khoảng luôn được trợ giúp bởi clustered index. Trở lại hai bảng trong ví dụ trên:
SELECT CustomerID,CustomerType FROM Sales.Customer WHERE CustomerID BETWEEN 20000 and 30000 SELECT CustomerID,CustomerType FROM Sales.Customer_NC WHERE CustomerID BETWEEN 20000 and 30000
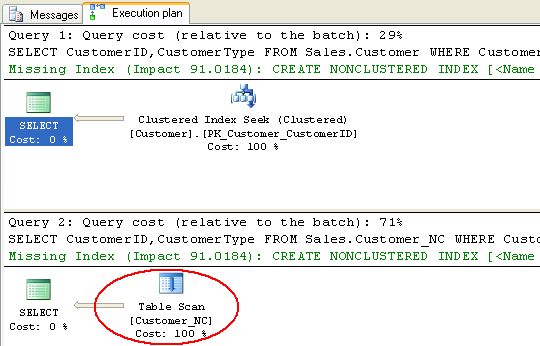
Hãy tạm bỏ qua dòng khuyến cáo (“Missing index…”) của SQL Server. Ta thấy là câu lệnh thứ nhất được thực hiện bằng index seek, trong khi câu lệnh thứ hai dẫn đến quét bảng (table scan) mặc dù trường cần tìm đã có index. Lý do là vì câu lệnh tìm kiếm theo khoảng như trên thường trả về nhiều bản ghi, nếu dùng index sẽ tạo ra nhiều thao tác bookmark lookup (mỗi bản ghi tìm được là một lần lookup), dẫn đến chi phí tăng cao. Trong trường hợp này nó còn vượt quá chi phí quét bảng. Vì thế bộ tối ưu hóa (Optimizer) khi đánh giá các phương án đã chọn cách quét bảng. Với clustered index thì thao tác nhảy thẳng đến từng node (index seek) luôn đủ để lấy được kết quả; vì index seek đã là tối ưu nên không có phương án nào khác cần xem xét.
Phiên bản áp dụng: Tất cả các phiên bản
Tags: clustered index, Index, Non-clustered index
20 Comments
Posted on 22/9/2010 | Categories: Index, Thiết kế database
Các bài viết tương tự
Index Giúp Tăng Hiệu Năng Thực Hiện Như Thế Nào Tối Ưu Hóa Câu Lệnh Bằng Covering Index Để Dùng Được Index Trong Điều Kiện Tìm Kiếm Của Câu Lệnh
Chuyên mục: Hỏi Đáp