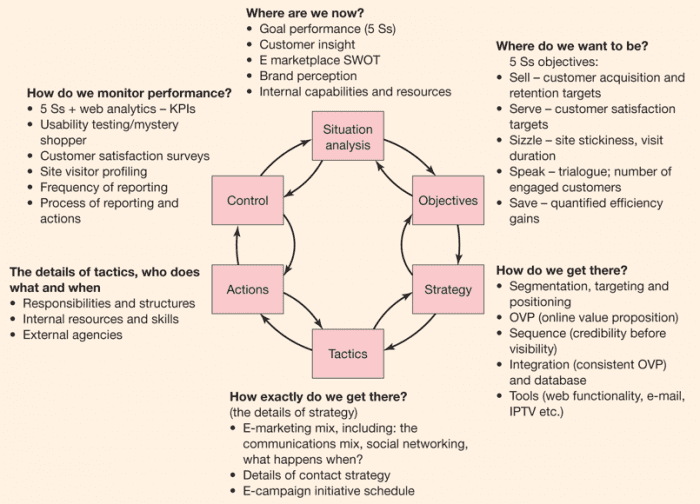
Chuỗi bài bài viết sẽ giới thiệu về nền tảng lý thuyết và cách áp dụng bộ lọc Kalman.
> Phần 1 – Lý thuyết cơ bản.
Bạn đang xem: Bộ lọc kalman là gì
Phần 2 – Áp dụng bộ lọc Kalman cho hệ 1 biến.
Phần 3 – Áp dụng bộ lọc Kalman cho hệ nhiều biến.
LỊCH SỬ RA ĐỜI
Bộ lọc Kalman được giới thiệu lần đầu tiên vào năm 1960 bởi Rudolf E. Kalman (1930 – 2016), một kỹ sư điện, nhà toán học, nhà phát minh người Mỹ gốc Hungary. Thực tế đã chứng tỏ bộ lọc Kalman là một khám phá tuyệt vời trong lĩnh vực “Statistical Estimation Theory”, cũng như là một trong những khám phá quan trọng nhất thế kỷ 20.
Ứng dụng đầu tiên và nổi tiếng nhất chính là bộ lọc Kalman đã được áp dụng để điều hướng cho Dự án Apollo, trong đó yêu cầu ước tính quỹ đạo của tàu vũ trụ có người lái lên Mặt trăng và quay trở lại Trái đất.
Mặc dù Bộ lọc Kalman được ứng dụng trong nhiều lĩnh vực, chẳng hạn như Process control, Tracking, Location & Navigation system,… nhưng nó được sử dụng chủ yếu với 2 mục đích chính:
Estimating the state of dynamic system (Ước tính trạng thái của hệ thống động) – trong đó, hệ thống động là hệ thống có trạng thái thay đổi theo thời gian, mà trong vũ trụ này thì hiếm có thứ nào hoàn toàn “constant”. Từ những thông tin chứa đầy nhiễu và sự không chắc chắn (noise & uncertainty), bộ lọc Kalman có thể cung cấp cho chúng ta các giá trị ước tính (chính xác nhất có thể) về trạng thái hiện tại của hệ thống.The Analysis of Estimation Systems – phần này mình chưa thực sự tìm hiểu nên không dám chém gió, đợi cao nhân nào đó ghé qua chỉ giáo thêm. KHÁI NIỆM VÀ KÝ HIỆU
Trước khi tìm hiểu về bộ lọc Kalman, chúng ta cần nắm các khái niệm sau:
System state,

– vector chứa các biến trạng thái của hệ thống;Measurement values,
– vector chứa các giá trị trạng thái đo được tại thời điểm k;Control input,
– vector chứa giá trị input của hệ thống tại thời điểm k;Posteriori state,
– giá trị ước tính của các biến trạng thái ở thời điểm k sau khi thực hiện phép đo
;Priori state,
– giá trị của các biến trạng thái ở thời điểm k được dự đoán từ trạng thái
;Dynamic Model (có khi được gọi là State Transition Model) – mô hình biểu diễn mối quan hệ giữa các trạng thái của hệ thống tại thời điểm k và k-1, được dùng để dự đoán Priori state;Measurement Noise – nhiễu trong quá trình đo đạc (sai số của cảm biến, sai số của dụng cụ đo,…);Process Noise – nhiễu trong quá trình hoạt động của hệ thống (tác động của môi trường). NỀN TẢNG LÝ THUYẾT
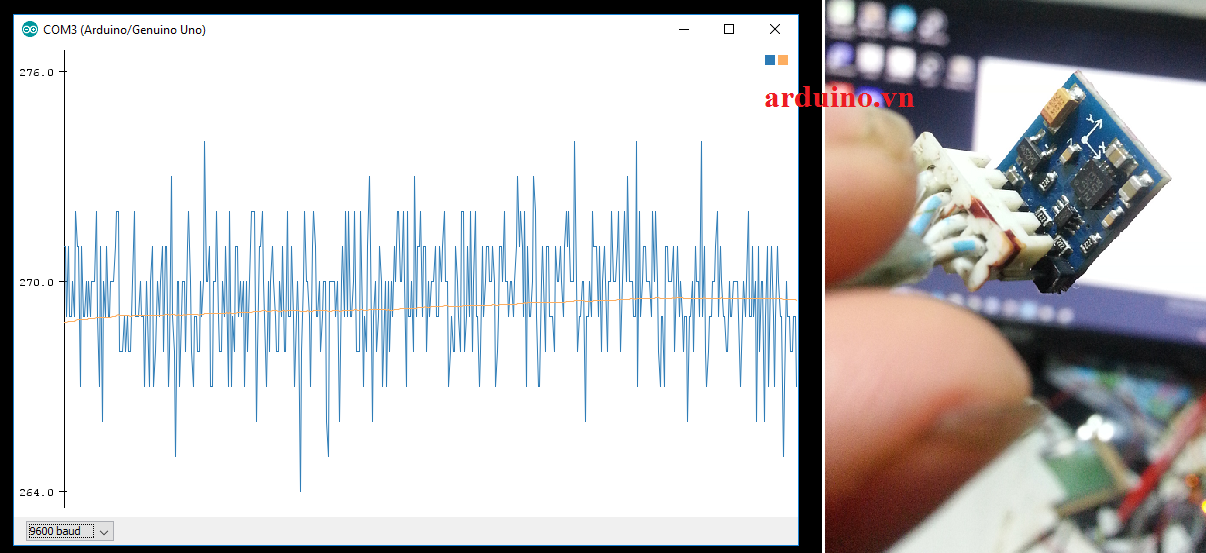
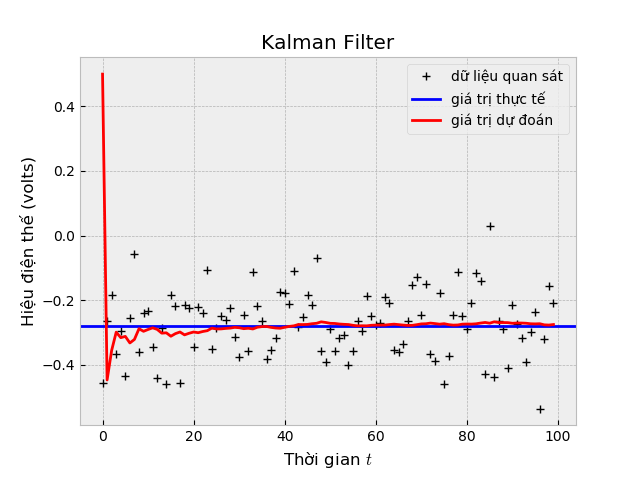
Để minh họa cho phần này, chúng ta sẽ sử dụng mô hình là một chiếc xe tự lái đang chuyển động trên một đường thẳng với 2 trạng thái cần theo dõi là: vị trí (position) và vận tốc (velocity).
Trên xe cũng có gắn thiết bị GPS để định vị với sai số 10 m, đây là con số khá lớn nếu chúng ta muốn xác định chính xác vị trí của chiếc xe. Ngoài ra, chiếc xe còn chịu ảnh hưởng của địa hình (chẳng hạn như ổ gà hay các đoạn đường gồ ghề), do đó xác định vị trí chiếc xe thông qua đồng hồ vận tốc là không thể chính xác.
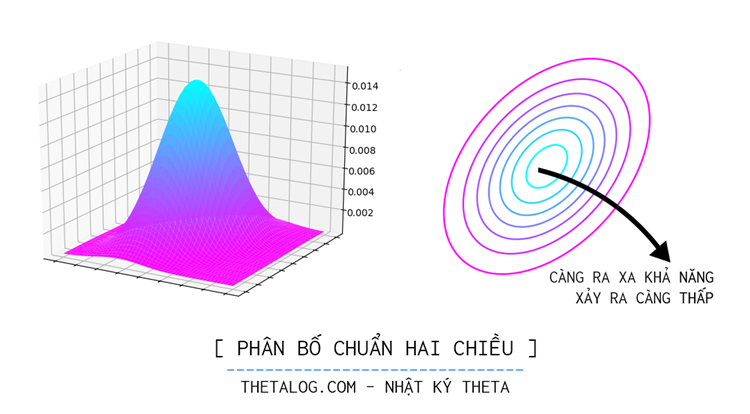
Chúng ta không biết vị trí và vận tốc thực sự của chiếc xe và bộ lọc Kalman sẽ giả định rằng 2 biến position và velocity là ngẫu nhiên và tuân theo phân phối Gaussian nhiều biến (Multivariate Gaussian Distribution), trong đó: biến position có giá trị kỳ vọng
và phương sai
, biến velocity có giá trị kỳ vọng
và phương sai
.
System state:
Vì giữa vận tốc và vị trí có mối quan hệ tỉ lệ thuận với nhau nên chúng ta sẽ có biểu đồ phân bố của 2 biến velocity và position có dạng như sau:
Để xác định sự phân tán của hệ trạng thái tại thời điểm k, chúng ta sử dụng Covariance Matrix (Ma trận hiệp phương sai), trong đó mỗi phần tử của ma trận biểu diễn giá trị Covariance (Hiệp phương sai) giữa 2 biến:
Trong đó,
DỰ ĐOÁN TRẠNG THÁI (PREDICT PHASE)
Để dự đoán (predict) priori state, chúng ta cần có Dynamic model, và trong ví dụ này, đó chính là các phương trình chuyển động của vật lý lớp 10. Có thể nói rằng, đây chính là dự đoán mang tính lý thuyết dựa trên trạng thái trước đó của hệ thống.
Các phương trình chuyển động được biểu diễn như sau (tạm thời chỉ quan tâm đến chuyển động đều):
Đưa về dạng ma trận:
Như vậy,
chính là Dynamic model của hệ thống.
Xem thêm: Tải Về Avatar 258 Auto Farm V1, Tải Avatar 2
Sau khi dự đoán được trạng thái mới của hệ thống, chúng ta cần cập nhật lại Ma trận hiệp phương sai của 2 biến ngẫu nhiên này:
Cho đến nay chúng ta mới chỉ quan tâm đến trường hợp chiếc xe chuyển động đều, vậy nếu trong quá trình hoạt động, chiếc xe cần giảm tốc (vì gặp đèn tín hiệu) hoặc tăng tốc (để vượt dốc) thì sao? Đây là lúc chúng ta cần thêm biến gia tốc
vào Dynamic model.
Đưa về dạng ma trận:


Trong đó,

được gọi là Control-input model;

được gọi là Control input.
Ngoài ra chúng ta cần quan tâm đến các tác động từ môi trường mà chúng ta không thể kiểm soát được (chẳng hạn như địa hình), vì thế mà trạng thái dự đoán được có thể không chính xác. Chúng ta sẽ mô phỏng các tác động này như nhiễu với mean
và hiệp phương sai
:

HIỆU CHỈNH TRẠNG THÁI (CORRECTION PHASE)
Ở phần này chúng ta sẽ sử dụng dữ liệu đọc được từ cảm biến để hiệu chỉnh trạng thái của hệ thống. Với trạng thái được dự đoán
, chúng ta mong muốn rằng trạng thái đo được từ cảm biến cũng sẽ gần giống như vậy:

Trong đó,
là Observation model, vì chúng ta có thể đo được giá trị 2 biến position và velocity nên
. Trong hệ thống mà chỉ có thể đo được biến velocity thì
Tất nhiên kết quả của phép đo (vị trí và vận tốc) không thể trùng với kết quả dự đoán trên lý thuyết vì nhiễu (Measurement noise), do đó nó cần được biểu diễn bởi một phân phối Gaussian nhiều biến có giá trị kỳ vọng là
, ma trận hiệp phương sai
.
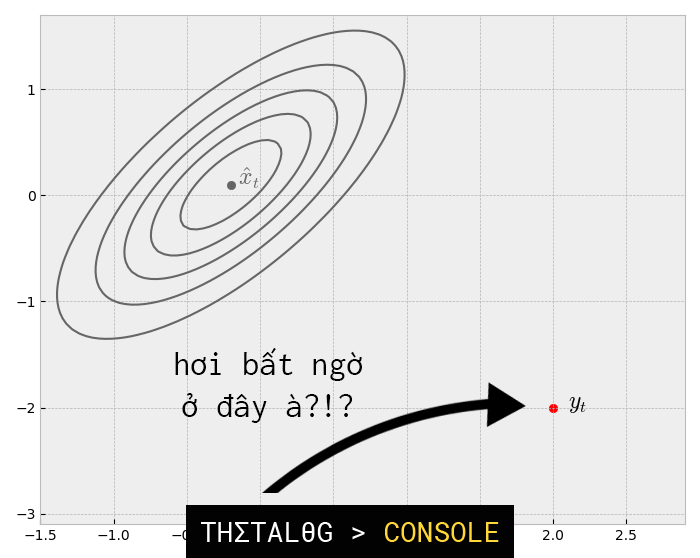
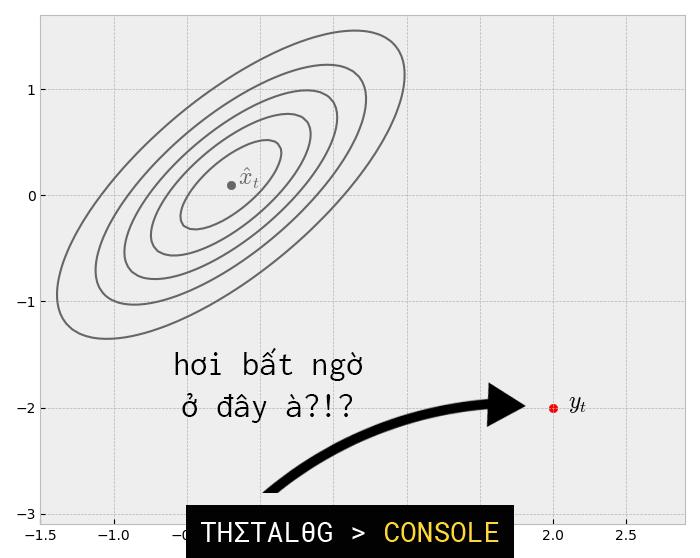
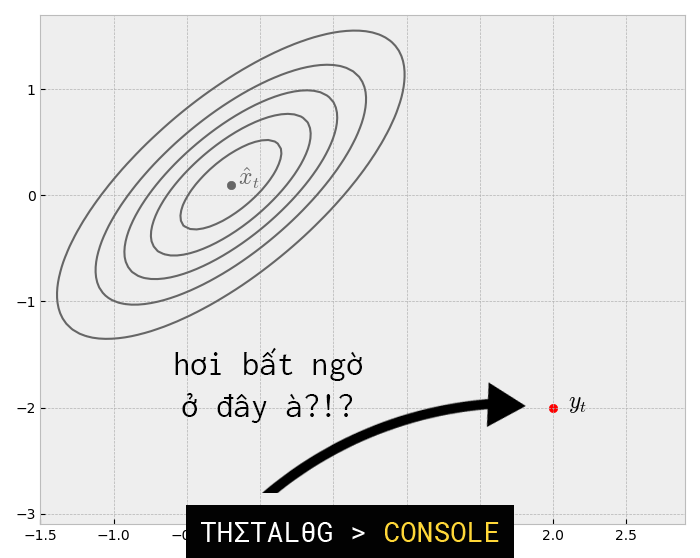
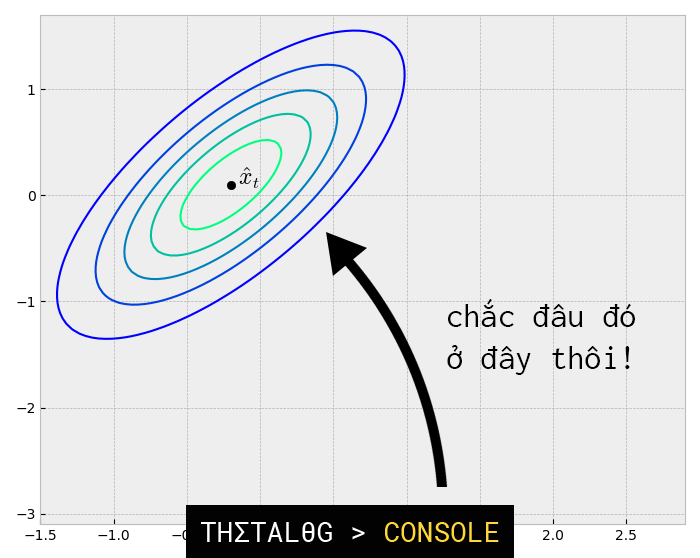
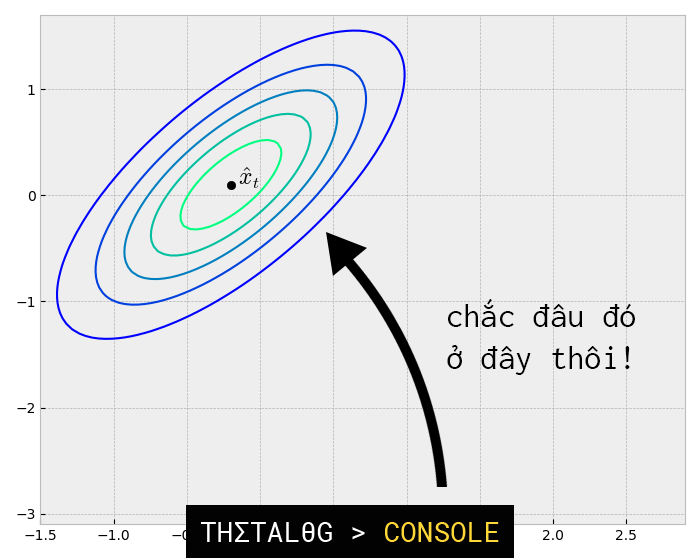
Như vậy đến thời điểm này chúng ta đã có 2 phân phối Gaussian (của trạng thái được dự đoán và của trạng thái đo được). Chúng ta sẽ biểu diễn 2 phân phối Gaussian như sau:
Phần giao nhau giữa 2 vùng trạng thái trên chính là kết quả ước tính tối ưu.
Nói một chút về toán học, để tìm ra phân phối của vùng giao nhau giữa 2 phân phối Gaussian (một biến), chúng ta cần thực hiện phép nhân giữa 2 phân phối đó:
Sau một loạt biến đổi, chúng ta sẽ nhận được:
Đặt
, ta nhận được:
Đối với phân phối Gaussian nhiều biến (Multivariate Gaussian Distribution), ta có:

Trong đó:

là ma trận hiệp phương sai (Covariance matrix) của phân phối Gaussian nhiều biến;

là ma trận đơn vị;

được gọi là ma trận Kalman Gain.
Quay trở lại với chiếc xe tự lái, chúng ta đã có 2 phân phối Gaussian nhiều biến:

và

, như vậy:


Chú ý: tham khảo mục để hiểu rõ hơn về các phép biến đổi trung gian.
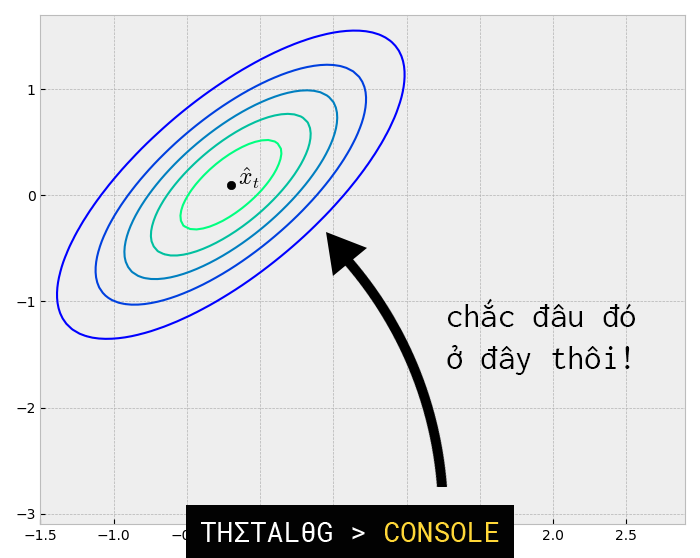
chính là trạng thái ước tính tốt nhất và nó sẽ được sử dụng để dự đoán trạng thái

ở thời điểm k+1, xem hình 5.
KẾT THÚC
Ở bài viết này chúng ta đã tìm hiểu về lý thuyết của bộ lọc Kalman. Vì vừa nghiên cứu, vừa viết bài để note lại nên có thể có nhiều thiếu sót, các cao nhân vui lòng chỉ giáo thêm.
Hẹn gặp lại các bạn ở phần 2 “Áp dụng bộ lọc Kalman cho hệ 1 biến” của loạt bài . Cảm ơn các bạn đã theo dõi bài viết.
Thân ái và quyết thắng.
Xem thêm: Trưởng Khoa Tiếng Anh Là Gì, Trưởng Khoa Trong Tiếng Tiếng Anh
References:
Kalman filter tutorial.
Embedded Systems Programming – Kalman filtering.
A practical approach to Kalman filter and how to implement it.
How a Kalman filter works, in pictures.
Kalman filtering: Theory and Practice using MATLAB, second edition.
Chuyên mục: Hỏi Đáp