Tháng 7/2019, nghiên cứu của một nhóm các nhà nghiên cứu từ Đại học California tại Irvine (Hoa Kỳ) về sử dụng thuật toán kết hợp học sâu (Deep Learning) và học tăng cường (Reinforcement Learning) trong việc “giải mã” các khối Rubik 3×3, đã được publish trên tạp chí khoa học Nature. Đây là một phương pháp được áp dụng khá phổ biến trong các cuộc thi về game hiện nay.
Đang xem: Cách chơi rubik 3x3x3 cho người mới chơi
Deep learning – học sâu là gì
Học sâu (Deep learning) đề cập đến một kỹ thuật để tạo ra trí tuệ nhân tạo bằng cách sử dụng một mạng lưới nơ ron thần kinh dạng lớp, tương tự như trong thiết kế trong bố trí của bộ não con người.
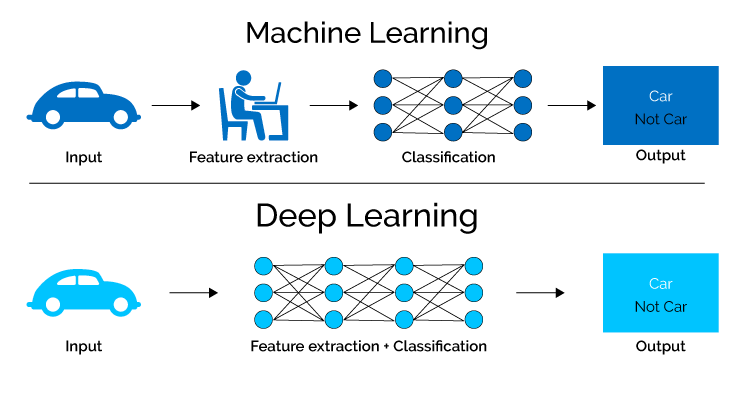
Nó phù hợp với một nhóm lớn hơn các kỹ thuật học máy nhằm mục đích dạy cho một máy tính để phân tích, thay vì sử dụng các thuật toán được xác định trước được xây dựng cho một nhiệm vụ cụ thể.
Sức mạnh phân tích mà phương pháp này cung cấp là hỗ trợ công nghệ tương lai như những chiếc xe không người lái, giúp họ nhận biết dấu hiệu đường bộ hoặc phân biệt giữa các vật thể chặn đường đi của nó…
Reinforcement learning – Học tăng cường là gì?
Học tăng cường – Reinforcement Learning hiện tại là khái niệm khá mới đối với đa số người Việt Nam. Đây lĩnh vực liên quan đến việc dạy cho máy (agent) thực hiện tốt một nhiệm vụ (task) bằng cách tương tác với môi trường (environment) thông qua hành động (action) và nhận được phần thưởng (reward). Cách học này rất giống với cách con người học từ môi trường bằng cách thử sai.
Ví dụ:
Vào mùa đông, khi đến gần lửa thì đứa trẻ sẽ thấy ấm, và nó sẽ có xu hướng đến gần lửa nhiều hơn (vì nhận được phần thưởng là sự ấm áp), nhưng khi chạm vào lửa nóng và bị bỏng, đứa trẻ sẽ có xu hướng tránh việc chạm vào lửa.
Trong ví dụ trên, phần thưởng xuất hiện ngay, việc điều chỉnh hành động là tương đối dễ. Tuy nhiên, trong các tình huống phức tạp hơn khi mà phần thưởng ở xa trong tương lai, điều này trở nên phức tạp hơn. Làm sao để đạt được tổng phần thưởng cao nhất trong suốt cả quá trình? Reinforcement Learning (RL) là các thuật toán để giải bài toán tối ưu này.
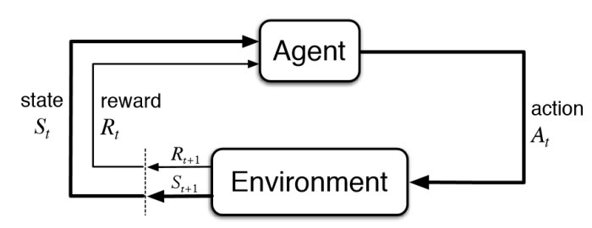
Một số thuật ngữ thường gặp:
Environment(môi trường): là không gian mà máy tương tác.Agent(máy): máy quan sát môi trường và sinh ra hành động tương ứng.Policy(chiến thuật): máy sẽ theo chiến thuật như thế nào để đạt được mục đích.Reward(phần thưởng): phần thưởng tương ứng từ môi trường mà máy nhận được khi thực hiện một hành động.State(trạng thái): trạng thái của môi trường mà máy nhận được.Episode(tập): một chuỗi các trạng thái và hành động cho đến trạng thái kết thúcS1, A1, S2, A2,…ST, ATAccumulative Reward(phần thưởng tích lũy): tổng phần thưởng tích lũy từ 1 state đến state cuối cùng. Như vậy, tại stateS, agent tương tác với environment với hành độngA, dẫn đến state mới St+1 và nhận được reward tương ứngRt+1. Vòng lặp như thế cho đến trạng thái cuối cùngST.
Trò chơi Rubic 3×3
Mọi người khá là quen thuộc với trò trơi này rồi. Rubik là một khối lập phương, ghép lại từ 27 khối lập phương nhỏ hơn, diện tích 3x3x3 với mặt khối lập phương nhỏ mang màu khác nhau. Bạn có thể xoay khối Rubik thế nào tùy thích, để đưa các khối lập phương nhỏ tới bất kỳ mặt nào. Cách chơi cũng đơn giản thôi: đối diện với một khối Rubik ở trong trạng thái scrambled (tạm dịch là đảo lộn), mỗi mặt có đủ thứ màu, bạn phải xoay khối lập phương sao cho mỗi mặt 3×3 của nó có cùng màu. Thứ đồ chơi này “Đơn giản” đến mức cha đẻ của nó, ông Ernő Rubik phải mất tới một tháng để giải được chính câu đố mình vừa phát minh ra.

Giáo sư kiến trúc, điêu khắc gia người Hungary, Ernő Rubik – Cha đẻ của khối Rubik
Đây là loại đồ chơi không những được trẻ em trên khắp thế giới yêu thích mà nó còn là món đồ chơi hấp dẫn với cả nhiều người lớn. Không chỉ giúp người chơi có những giây phút thư giãn, giải trí với những vòng xoay tùy ý quanh chiếc Rubik mà còn giúp người chơi, đặc biệt là trẻ em nâng cao khả năng tư duy và phát triển trí não rất tốt so với những loại đồ chơi thông thường khác. Người chơi đã tạo ra rất nhiều cách giải và chiến thuật khác nhau để chơi thành công khối Rubik. Những “cuber” (biệt danh của người chơi Rubik) với những đầu ngón tay giải đố thành thạo có thể hoàn thành một khối Rubik chỉ trong vài giây. Kỷ lục thế giới hiện tại là 3,47 giây do Yusheng Du – người Trung Quốc nắm giữ.
Xem thêm: phần mềm chuyển đổi pdf sang word

Yusheng Du – người Trung Quốc nắm giữ kỷ lục thế giới về giải thành công Rubik 3x3x3 trong 3,47s
Hiện nay, Rubik có nhiều phiên bản khác nhau. Đó là các phiên bản lập phương chính với 6 mặt: 2x2x2 (được gọi tên là khối bỏ túi), 3x3x3 ( khối tiêu chuẩn), 4x4x4 (khối báo thù), 5x5x5 (khối Rubik giáo sư), 6x6x6 (V-Cube 6) và 7x7x7 ( V-Cube 7). Phiên bản Rubik được nhắc đến trong phạm vi bài viết này là Khối tiêu chuẩn 3x3x3.
A.I giải khối Rubik 3x3x3 trong 1,2 giây?
Với sự phát triển không ngừng của ngành khoa học Trí tuệ nhân tạo, các nhà khoa học về máy tính và thống kê từ Đại học California tại Irvine (Hoa Kỳ) đã đặt ra cho mình một thử thách không hề đơn giản, đó là việc áp dụng Trí tuệ nhân tạo vào trò chơi cùng những chiếc Rubik 3×3 quen thuộc. Họ đã tạo ra được một hệ thống trí tuệ nhân tạo có thể giải quyết các khối Rubik trong thời gian trung bình là 1,2 giây với khoảng 20 lần di chuyển, nhanh hơn nhiều so với kỉ lục thế giới hiện tại.
Vòng lặp THỬ và SAI
Giống như việc DeepMind tạo ra AlphaGo trong trò chơi Cờ vây, các nhà khoa học của Đại học California đã liên tiếp đưa các dữ liệu về trò chơi vào hệ thống máy tính thông qua thuật toán về học sâu (Deep Learning) và học tăng cường (Reinforcement Learning) để máy tự học và tự rút ra bài học sau đó tự tiến bộ.
Nguyên tắc cơ bản được sử dụng ở đây là tiến hành THỬ và SAI. Thuật toán cho phép máy tính thử một giải pháp, sau đó, tín hiệu tích cực (được gọi là phần thưởng) hoặc tiêu cực sẽ được hệ thống phản hồi lại. Trí tuệ nhân tạo sẽ bắt đầu lại theo phản hồi mà nó đã nhận được, và nó sẽ lại nhận được tín hiệu mới, vvv. cho đến khi nó dần cải thiện và đi đến kết quả mong đợi. Nói cách khác, trí tuệ nhân tạo đã tự cải thiện thuật toán của chính nó.
“Lộn ngược vấn đề” để giải quyết nó
Để giải quyết bài toán và tránh việc phải phải lặp đi lặp lại quá trình “thử” một cách vô tận, các nhà nghiên cứu đã xây dựng thuật toán bắt đầu từ kết quả cuối cùng.
Đầu tiên, họ đã cung cấp cho máy dữ liệu của một khối Rubik đã được xếp thành công. Sau đó, họ xoay khối lập phương thành hàng ngàn kết hợp khác nhau, thuật toán sẽ quan sát các chuyển động này từ 1000 đến 10.000 chuyển động. Bằng cách tổng hợp các thông tin, nó học cách phân tích cách để có thể giải mã khối Rubik. Cuối cùng, một thuật toán mới sẽ được xây dựng để tái tạo lại quá trình đó, và chúng ta được biết đến nó với cái tên DeepCubeA.
Kết quả là…
Trong báo cáo nghiên cứu của mình, các tác giả cho biết rằng DeepCubeA đã tìm thấy giải pháp trong 100% các bài kiểm tra. Trong đó, 60,3% đã được DeepCubeA đã tìm ra con đường ngắn nhất để đến đến với đáp án. Và gần 40% còn lại thì kết quả nhận được cũng không nằm xa giải pháp tối ưu này (cụ thể: 36,4% chỉ cần thêm hai chuyển động và 3,3% cần thêm bốn chuyển động để giải khối lập phương). Theo kết quả được công bố, chỉ cần trung bình 1,2 giây với khoảng 20 chuyển động để DeepCubeA xếp thành công 1 khối Rubik ở trạng thái ban đầu bất kì.
Đặc biệt, từ lần đầu nhìn thấy khối Rubik hoàn thiện, DeepCubeA chỉ mất 2 ngày để đưa ra được “chiến lược” xử lý riêng thông qua mạng thần kinh tương tự cách não người xử lý thông tin, kết hợp với một số thủ thuật học máy khác mà gần như không cần tới sự tương tác của con người. Nó cũng liên tục cải thiện năng lực hoàn thiện khối Rubik với các mô hình xếp khó hơn.
Tuy nhiên, nếu chỉ xét về tốc độ, DeepCubeA lại chưa phải hệ thống xếp Rubik nhanh nhất hiện nay. Cỗ máy tự động min2phase của trường đại học Massachusetts (MIT) hiện giữ kỷ lục thời gian xếp Rubik, chỉ khoảng 0,38 giây.
Trong phạm vi bài viết này, DeepCubeA được đánh giá cao hơn vì min2phase vận hành dựa trên thuật toán cứng và được tối ưu cao độ chứ không phải trí tuệ nhân tạo tự suy. Nói cách khác, min2phase được thiết kế tập trung vào việc xử lý Rubik tối ưu nhất ngay từ đầu, còn DeepCubeA phải tự mày mò tìm ra cách mà nó cho là tối ưu.
Đặc biệt, điều thú vị còn nằm ở chỗ, tới nay, các nhà nghiên cứu vẫn chưa làm rõ được tại sao DeepCubeA có thể tự “mò mẫm” ra các thủ thuật xếp hoàn thiện Rubik, dù họ chỉ cho hệ thống này xem một lần phiên bản hoàn thiện của Rubik với mỗi mặt chỉ có một màu duy nhất mà không hề chỉ bảo các phương thức hay thủ thuật xếp.
Xem thêm: #1 : Cách Chơi Janna Sp Mùa 7, Cách Lên Đồ Janna Sp, Bảng Ngọc Và Khắc Chế Janna
Tạm kết
Như vậy, cho đến nay, trí tuệ nhân tạo đã đánh bại được một trong những cờ thủ cờ vây nổi tiếng trong lịch sử cũng như vượt qua kỉ lục thế giới về thời gian xếp Rubik. Đây có thể được coi là một lời khẳng định cho sự phát triển không ngừng trong tương lai của lĩnh vực này nhưng đồng thời nó càng làm khơi dậy những suy nghĩ tiêu cực về một tương lai khi mà trí tuệ nhân tạo trở thành mối nguy hại cho con người giống như những gì mà Skynet trong bộ phim khoa học viễn tưởng Terminator đã làm…